Ldfa
-
Compteur de contenus
30 213 -
Inscription
-
Dernière visite
-
Jours gagnés
1 184














Ldfa's Achievements
")





-
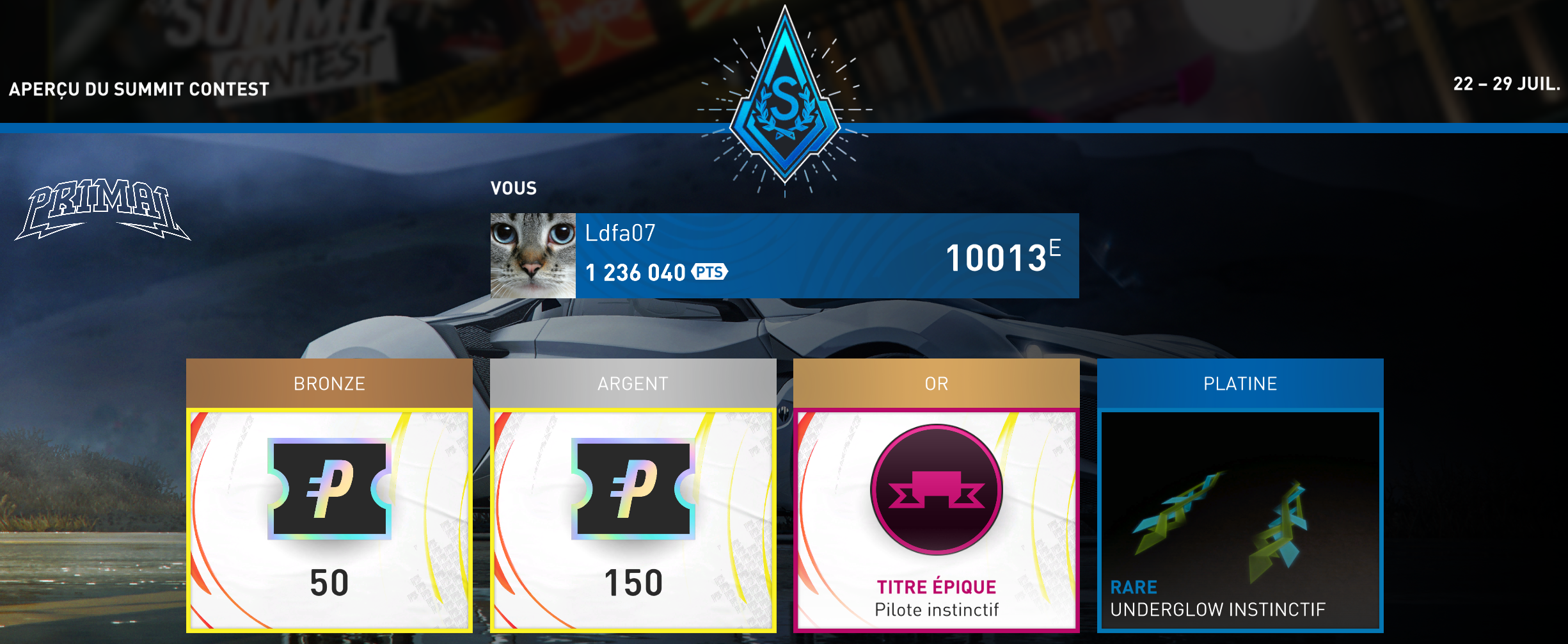
Je termine encore Platine cette semaine ici aussi.

-
 POLAURENT a réagi à un message dans un sujet :
Maxthon 7.5.2.9400 Bêta pour Windows est sorti
POLAURENT a réagi à un message dans un sujet :
Maxthon 7.5.2.9400 Bêta pour Windows est sorti
-
POLAURENT a réagi à un message dans un sujet :
Maxthon 7.5.2.9400 Bêta pour Windows est sorti
-
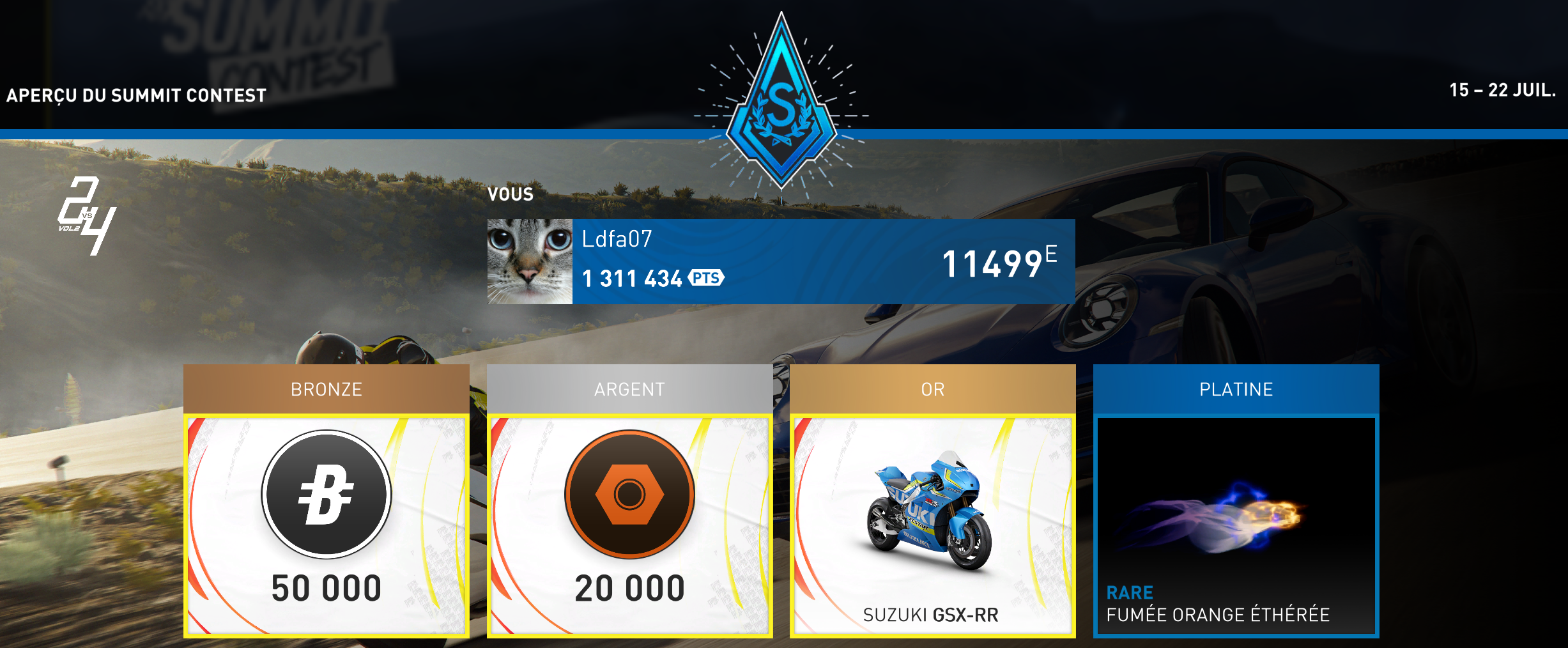
Je termine encore Platine cette semaine.
-
bearly a réagi à un message dans un sujet :
Maxthon 7.5.2.9400 Bêta pour Windows est sorti
-
bearly a réagi à un message dans un sujet :
Maxthon 7.5.2.9400 Bêta pour Windows est sorti
-

Win Traduction française de Mx7 pour Windows
Ldfa a répondu à un(e) sujet de Ldfa dans Traductions françaises de Maxthon sur Crowdin
Traduction approuvée, on dirait que Maxthon se préparer à passer la main sur son navigateur à son IA maison, c'est très tendance... fr.ini -
Win Traduction française de Mx7 pour Windows
Ldfa a répondu à un(e) sujet de Ldfa dans Traductions françaises de Maxthon sur Crowdin
There are new strings to translate in the Maxthon pour Windows project. You were a project participant previously so your help will be appreciated a lot. 5 new strings for translation (16 words). -
Changements principaux : + Ajout d'une invite de mise à jour vers Maxnote V2 pour aider les utilisateurs à comprendre l'état de la mise à jour de leurs notes. + Ajout de la prise en charge du double-clic sur une note dans la liste de gestion de Maxnote pour l'ouvrir directement en vue de sa modification. * Amélioration du processus de connexion automatique lors du retour à la page de connexion après une déconnexion du réseau. * Amélioration de la logique de connexion pour un processus de connexion plus fluide. - Correction d'un problème empêchant l'affichage du répertoire simplifié des notes pour certains utilisateurs. - Correction de plantages connus.
-
Maxthon 7.5.2.9400 Bêta pour Windows est sorti aujourd'hui, il apporte son lot de nouvelles fonctionnalités, d'améliorations et de corrections de bugs. Téléchargement : https://github.com/maxthon/Maxthon/releases Les changements en français sont là. Vous pouvez également vous abonner au groupe Telegram NBdomain & MX6 pour faire remonter vos demandes d'améliorations et bugs rencontrés. Source : https://forum.maxthon.com/d/5913-maxthon-pc-7529400
-
GPS Doully sur Waze - Le GPS le plus éclaté de la route - Korben
Ldfa a posté un sujet dans Mon Wallabag
Korben Publié le 26 juillet 2026 Par Korben, Manuel Dorne korben.info Environ 1 minute de lecture Vous connaissez Doully ? Mais siii, l'humoriste avec la voix la plus cassée du stand-up français ? Perso je l'aime bien, elle est aussi trash que drôle et aujourd'hui, elle a mis en ligne son propre guidage vocal pour Waze, avec le lien qui va bien pour l'installer dans votre bagnole. Avant que vous vous fassiez des idées, non, elle n'est pas motorisée au Jack Daniel's. C'est sa vraie voix tout simplement. Elle le répète à qui veut l'entendre : "Non je ne suis pas bourrée, et oui je suis née avec cette voix et cette diction de clocharde". On ne choisit pas. Pour ceux qui ne l'ont jamais entendue, voici un extrait de son spectacle Hier j'arrête, comme ça vous saurez à quoi vous attendre au prochain rond-poin Ce clic autorise une connexion à Google : adresse IP transmise et traceurs possibles. En savoir plus >}} Le truc marrant, c'est que ce n'est pas un pack de voix de star négocié à coups de contrats avec Google. Elle a tout simplement utilisé la fonction voix personnalisée de Waze, dispo pour tous dans votre téléphone. Si vous voulez faire pareil qu'elle, direction les réglages de son, "Nouvelle voix", et il ne reste plus qu'à enregistrer les phrases une par une avant de baptiser le tout. Et hop, ça apparaîtra dans la liste. Et vous pouvez ensuite la refiler aux copains. Dans "Voix personnalisées", balayage vers la gauche, "Partager", et l'appli génère un lien. Bref, c'est ce qu'a fait Doully pour sa communaut� >}} Un point à connaître quand même avant de partir sur l'autoroute des vacances avec Doully à fond dans les haut-parleurs : Waze réserve les noms de rues aux voix qui portent la mention "Avec les noms de rue" dans la liste. Comme une voix enregistrée au micro dans son salon ne peut évidemment pas deviner le nom de votre départementale préférée, vous aurez les virages et les alertes façon Doully, mais pas l'adresse. C'est la vie, soyez fort ! Voilà, en tout cas, je trouve que c'est une super idée, donc c'est pour ça que je relaie ça ici. Sur mon Waze c'est installé en tout cas ! Pour ceux que ça intéresse, la voix de Doully, c'est par ici , à ouvrir depuis le téléphone où Waze est installé >}} Le GPS le plus éclaté de la route, c'est cadea Afficher l’article complet -
Linux DockPanel - Le panel web qui gère tout votre serveur - Korben
Ldfa a répondu à un(e) sujet de Ldfa dans Mon Wallabag
J'ai installé très simplement sur le script sur un conteneur Debian LXC sur un de mes serveur Proxmox et tout fonctionne à merveille. -
Linux DockPanel - Le panel web qui gère tout votre serveur - Korben
Ldfa a posté un sujet dans Mon Wallabag
Korben Publié le 25 juillet 2026 Par Korben, Manuel Dorne korben.info Environ 3 minutes de lecture Gérer un serveur à la main, c'est nginx à configurer, les certificats à renouveler, les sauvegardes à planifier et les conteneurs à surveiller... C'est beaucoup de travail. Mais vous allez avoir de l'aide grâce à DockPanel, d'Ovidiu Drobotă, qui met tout ça derrière une jolie interface web tenant dans 19 Mo de RAM. L'installation se colle en une ligne sur un VPS frais et vous récupérez un panneau d'admin sur le port 8443. Ubuntu, Debian, Rocky, Fedora ou Amazon Linux, en x86_64 comme en ARM64. À partir de là vous créez des sites en PHP, Node ou Python, avec nginx configuré tout seul et les certificats Let's Encrypt qui se renouvellent sans y penser. Les bases MySQL et PostgreSQL vont avec, navigateur SQL intégré et restauration à un instant T via les journaux binaires. Ensuite, c'est surtout le catalogue Docker qui fait le gros du travail. Environ 150 modèles en un clic répartis sur 14 catégories, WordPress, Postgres, Grafana, n8n ou Immich, et le reverse proxy, le SSL et le réseau se câblent automatiquement derrière. Les conteneurs inactifs peuvent même se mettre en veille tout seuls pour libérer la machine. Je vous parlais l'an dernier de Coolify pour le déploiement en self-hosted , et avant ça de aaPanel, le clone gratuit de cPanel mais aucun des deux ne couvre autant de terrain. Côté déploiement, vous poussez votre code et ça part en production, avec bascule atomique par lien symbolique et retour arrière en un clic quand le déploiement du vendredi tourne mal. Nixpacks reconnaît plus de 30 langages, donc pas de Dockerfile à écrire, et chaque branche peut avoir son environnement de préversion. Il y a aussi un serveur mail complet, Postfix, Dovecot et DKIM, avec Roundcube en webmail et Rspamd contre le spam. La partie DNS pilote Cloudflare et PowerDNS, avec vérification de propagation, DNSSEC et les tunnels Cloudflare. Un module CDN gère BunnyCDN et Cloudflare, purge du cache comprise. Pour la surveillance, des sondes HTTP, TCP et ping, une gestion d'incidents avec chronologie et post-mortem, une page de statut publique à laquelle vos utilisateurs peuvent s'abonner, et des alertes qui partent sur Slack, Discord ou PagerDuty. Un point de collecte Prometheus est dispo, avec un tableau Grafana prêt à importer. La sécurité est activée par défaut avec pare-feu applicatif ModSecurity par site, Fail2Ban, durcissement SSH en un clic, connexion par passkey ou 2FA, et chaque image Docker déployée peut être scannée à la recherche de CVE avec grype, avec refus de déploiement au-dessus du seuil que vous fixez. Les sauvegardes passent par Restic, chiffrées et dédupliquées, vers S3, SFTP, B2 ou GCS, avec vérification de restauration. Le reste ensuite, c'est que du confort. Terminal web avec enregistrement de session, gestionnaire de fichiers, palette de commandes en Ctrl+K, 6 thèmes, boîte à secrets chiffrée, passerelle à webhooks et une ligne de commande. La configuration complète s'exporte en YAML pour être rejouée ailleurs. Si vous gérez plusieurs machines, un seul panneau les pilote toutes, avec des comptes revendeur en marque blanche pour ceux que ça intéresse. Deux choses à savoir avant de lancer l'installation quand même... En mars, une injection de commande dans le formulaire de création de site a permis à un visiteur de passer root sur la machine de l'auteur. C'est corrigé depuis, mais l'agent tourne en root par conception puisque c'est lui qui touche à Docker, à nginx et aux certificats. L'autre point, c'est la licence. DockPanel est en Business Source License 1.1, ce qui n'est pas de l'open source même si la page d'accueil le présente comme ça. L'usage est libre et gratuit sur vos propres serveurs, mais la revente en service hébergé est interdite. Une bascule en MIT est quand même programmée pour mars 2030. Voilà, je me suis dit que ça pourrait vous intéresser. Source Afficher l’article complet -
IT-Connect Publié le 24 juillet 2026 Par Florian BURNEL it-connect.fr Environ 3 minutes de lecture Un diaporama, son éditeur, son mode présentateur, ses polices, ses images et ses données : le tout dans un fichier HTML d'environ 570 Ko. C'est la promesse de Bento, un projet open source très récent. Pas d'installation, pas de compte, pas de cloud, et surtout, un seul fichier. Le dépôt nyblnet/bento a été créé le 17 juillet 2026 sur GitHub et il compte déjà plus de 1 200 étoiles. Le principe : la suite bureautique qui tient dans un fichier. Bon, c'est un peu exagéré dans l'état actuel des choses puisque Bento sert uniquement à créer des présentations, mais c'est un bon début. L'idée est bonne et ce projet a été créé en une semaine à l'aide de Claude Code (l'auteur ne s'en cache pas). En pratique, il suffit de télécharger le fichier HTML de Bento et de l'ouvrir avec un navigateur. Ce fichier en lui-même représente l'application. Vous éditez vos diapositives, vous les présentez, vous enregistrez, et le fichier se réécrit lui-même en y intégrant votre document. Vous l'envoyez ensuite par e-mail et votre destinataire n'a besoin de rien d'autre qu'un navigateur pour le lire ou le modifier. À ne pas confondre : Bento n'a aucun lien avec BentoPDF, la boîte à outils PDF côté client (fusion, découpage, OCR, chiffrement) que j'ai déjà présentée dans un autre article. Auteurs différents, dépôts différents, licences différentes, aucune dépendance commune. Seule la philosophie rapproche les deux projets : un traitement entièrement local. Un fichier HTML qui se réécrit lui-même L'architecture décrite par le projet repose sur deux blocs distincts à l'intérieur du même fichier. Le premier est un bloc JSON placé en haut du document, qui contient les données du diaporama. Le second est l'application elle-même, embarquée sous forme de blob encodé en base64 et décompressée à la volée dans le navigateur via l'API DecompressionStream. Cette compression explique la taille contenue du livrable, d'après les explications données par l'auteur sur Hacker News. Pour l'enregistrement, Bento s'appuie sur une API afin de réécrire le fichier ouvert, avec un repli sur un simple téléchargement lorsque le navigateur ne la prend pas en charge. Côté fonctionnalités, on retrouve au sein d'un seul et même fichier, tout ça : Un moteur d'animation maison, avec des effets entre diapositives (les éléments partageant un même identifiant s'animent d'une slide à l'autre). Un moteur de graphiques maison (barres, lignes, secteurs, nuages de points), interactif pendant la présentation. Le mode présentateur, les commentaires, les gabarits, les tracés de courbes et de connecteurs, l'export PDF et 8 langues d'interface. La collaboration en direct chiffrée de bout en bout, avec un CRDT développé en interne. Collaboration chiffrée : le serveur ne voit rien La collaboration temps réel ne passe pas par un service qui héberge vos documents. Les clés sont générées côté client à la création du document et vivent dans le fichier lui-même. En clair : posséder le fichier, c'est appartenir au groupe, et une rotation des clés vaut révocation. Le relais de synchronisation optionnel est décrit comme "aveugle" par le projet. Selon l'auteur, il s'agit d'un petit service tournant sur Cloudflare Durable Objects, chaque diaporama disposant de son propre objet. D'après la documentation du dépôt, ce relais ne voit que trois choses : des données chiffrées (AES-GCM), les temps de connexion et une empreinte de la clé de session. Ni le contenu, ni les noms, ni la structure du document. Le mode collaboratif est facultatif, c'est pour cette raison qu'il y a un mode hors ligne. Il permet de bloquer toute connexion réseau, ce qui bloque les vérifications de mise à jour et la collaboration. Au-delà du fait qu'il soit utilisable de façon interactive sur un ordinateur ou un smartphone, Bento a été pensé pour les agents IA. Le document étant du JSON en clair dans un bloc de texte, n'importe quel assistant capable de lire et d'écrire un fichier peut modifier un .bento.html sur place, sans plugin ni API. Dans cette optique, le dépôt GitHub propose d'ailleurs un fichier agents.md et un plugin pour Claude Code (installable via /plugin marketplace add nyblnet/bento), capable de télécharger lui-même la dernière version signée de l'application. Bento/Slides est présenté comme la première application d'une suite plus large : Bento/Suite. La suite déjà prévue : un traitement de texte (bento/docs) et un tableur (bento/sheets). Quant au modèle économique, il n'y en a pas. Le projet est entièrement sous licence MIT. Qu'en pensez-vous ? Voir le projet Bento sur GitHub Cofondateur d'IT-Connect et Microsoft MVP "Cloud and Datacenter Management". Mon obsession depuis près de 15 ans ? Rendre l'administration système et la cybersécurité accessibles, que vous soyez junior ou confirmé. Plus qu'un métier, l'IT est pour moi une véritable passion. J’accompagne au quotidien les sysadmins et les professionnels de l’IT dans leur montée en compétences et leur veille technique. Afficher l’article complet
-
IA Mon nouvel ami qui sait tout sur tout #chatGPT - Korben.info
Ldfa a répondu à un(e) sujet de Ldfa dans Mon Wallabag
L'avis de Korben sur le sujet précédent : https://korben.info/openai-modeles-piratent-hugging-face-triche-benchmark.html -
BBS late.sh - Le BBS ressuscité en SSH, avec NetHack dedans - Korben
Ldfa a répondu à un(e) sujet de Ldfa dans Mon Wallabag
J'adore !!! -
BBS late.sh - Le BBS ressuscité en SSH, avec NetHack dedans - Korben
Ldfa a posté un sujet dans Mon Wallabag
Korben Publié le 22 juillet 2026 Par Korben, Manuel Dorne korben.info Environ 2 minutes de lecture Vous tapez dans votre terminal ssh late.sh et c'est tout. Votre clé SSH fait alors office de carte de membre et vous voilà dans un salon peuplé de gens qui tapent sur leur clavier depuis un peu partout sur la planète. C'est ce qu'a imaginé Mateusz Piórowski, un dev polonais, qui a passé ces derniers mois à ressusciter le BBS. Vous atterrissez dans THE LATE BAR, un vrai décor en ASCII où vous marchez en utilisant les flèches du clavier ou les touches hjkl . Vous vous asseyez avec s , vous faites coucou avec w , et la touche i ouvre la ligne de saisie pour parler. Y'a un barman, un jukebox, un salon à côté, des habitués affalés aux tables et une porte mystérieuse marquée DOORS... THE LATE BAR, vu depuis la démo web en lecture seule de late.sh Le reste du club tient dans le même terminal avec une radio qui tourne en fond, un tableau ASCII collaboratif dont chaque case garde le nom de qui l'a peinte, des profils pour dire sur quoi vous bossez, un fil de news et une arcade avec 2048, sudoku, nonogrammes et solitaire. Il y a même un bonsaï qui pousse pendant que vous codez. Mais je reviens un peu sur cette porte mystérieuse dont je vous parlais juste avant… Derrière se cachent ce qu'on appelle les door games. Pour les moins de 40 ans, dans les années 90, un "door" c'était le jeu externe qu'un BBS lançait pour vous, le temps de votre session. C'était le cœur social de ces machines, et si vous voulez goûter un peu à l'ambiance de l'époque, l'opération Sundevil vous en donnera un bon aperçu. Le bien inspiré Piórowski les a donc remis en ligne ! Et ce sont les vrais, hein, pas des remakes. On y trouve par exemple NetHack, Dope Wars, Dungeon Crawl Stone Soup ou encore Usurper. Chaque jeu a sa crate Rust dédiée qui lance le vrai binaire Unix sur un PTY et vous le proxifie dans votre session SSH. Vous pouvez également faire tout tourner chez vous en clonant le dépôt puis en faisant un make start , puis vous connecter en ssh localhost -p 2222 . Un CLI compagnon gèrera alors la lecture audio en local avec un visualiseur synchronisé. Côté vie privée, sachez que le serveur garde l'empreinte de votre clé, et pas la clé publique entière, et vos scores comme vos messages n'y sont rattachés que par cette empreinte. Il n'y a aucun log d'IP ni d'analytics mais si vous restez méfiant vous pouvez générer une clé jetable et vous connecter avec : ssh-keygen -t ed25519 -f ~/.ssh/late_throwaway ssh -o IdentitiesOnly=yes -i ~/.ssh/late_throwaway late.sh Après c'est pas l'open, source, puisque le code est publié sous licence FSL-1.1-MIT. Vous pouvez donc lire, auditer, modifier, forker et contribuer, mais pas monter un service public concurrent. Quoi qu'il en soit, chaque version bascule ensuite sous licence MIT, 2 ans après sa sortie. Piórowski assume ça très bien et le documente dans son dépôt. L'autre limite, c'est la taille car toute l'infra tourne sur un seul nœud Kubernetes plafonné à 1000 connexions simultanées, donc autant dire que le service va rapidement être victime de son succès Mais moi j'ai trouvé ça super cool, c'est pour ça que je vous le partage. Je vous ai montré Soft Serve pour héberger son Git en SSH , The Lounge pour garder IRC en vie , Ascii Patrol pour jouer en caractères ... et voilà maintenant un salon complet qui revient ! Bref, ssh late.sh et vous verrez bien ce que ça donne ! Source Afficher l’article complet
-
Je termine encore Platine cette semaine ici aussi.
-
IA Mon nouvel ami qui sait tout sur tout #chatGPT - Korben.info
Ldfa a répondu à un(e) sujet de Ldfa dans Mon Wallabag
Les IA se défoulent en lançant des cyberattaques : https://www.01net.com/actualites/openai-perdu-controle-deux-ia-lance-cyberattaque-sans-precedent.html