Rechercher dans la communauté
Affichage des résultats pour les étiquettes 'Linux'.
18 résultats trouvés
-

Linux BentoPDF : la boite à outils PDF dans votre navigateur Web - IT Connect
Ldfa a posté un sujet dans Mon Wallabag
IT-Connect Publié le 26 janvier 2026 Par Florian BURNEL it-connect.fr Environ 5 minutes de lecture BentoPDF se présente comme une alternative à Stirling, PDFgear voire même à Adobe Acrobat dans une moindre mesure. Cette boite à outils PDF accessible directement dans votre navigateur Web regroupe des dizaines d'outils pour manipuler vos documents. Au-delà d'être open source, elle se veut respectueuse de la vie privée. Cet article explique comment installer votre instance de BentoPDF à l'aide de Docker. BentoPDF n'est pas la seule boite à outils PDF accessible directement depuis un navigateur et auto-hébergeable : Stirling-PDF reste une référence dans ce domaine, avec en complément des applications pour les ordinateurs. Pour autant, BentoPDF suscite de l'intérêt, la preuve : son nombre d'étoiles sur GitHub est passé de 0 à plus de 10 000 en à peine 3 mois. Voici les avantages de la solution BentoPDF : Application 100% client-side : un gros plus pour la confidentialité, car le traitement s'effectue dans le navigateur de l'utilisateur. Cela signifie que votre fichier n'est pas chargé sur le serveur où est installé BentoPDF. Libre d'accès : l'application est accessible sans authentification, ni compte. Tous les outils du toolkit sont gratuits, sans limitation, que ce soit pour traiter 1 ou X documents. Mode hors ligne pour l'accès aux outils. Conformité RGPD, CCPA et HIPAA. Ce projet open source est distribué sous licence AGPL-3.0. Des licences commerciales abordables sont proposées à ceux qui veulent intégrer BentoPDF au sein d'outils propriétaires (ou en source fermée). Je vous recommande de consulter cette page pour bien comprendre les subtilités selon les cas d'usage. Pour utiliser les outils de BentoPDF, vous avez plusieurs options : l'utiliser directement en ligne depuis le site web de la solution ou l'auto-héberger sur un ordinateur, un serveur ou encore un NAS. Aujourd'hui, je vous propose d'installer BentoPDF à l'aide de Docker Compose. Site officiel - BentoPDF GitHub - bentopdf Les outils de BentoPDF Les nombreux outils de BentoPDF sont organisés au sein de plusieurs catégories. On retrouve notamment : Éditer et annoter Dans la catégorie "Edit & Annotate", BentoPDF met à votre disposition des outils pour retravailler vos documents en profondeur. L'outil central est le PDF Editor, qui transforme votre fichier en espace de travail : vous pouvez y annoter du texte, surligner des passages, ou encore insérer des images et des formes. Il est accompagné par d'autres outils pour générer une table des matières, compléter un formulaire, signer un PDF, supprimer les pages blanches ou encore ajouter un filigrane. Ci-dessous un aperçu de l'outil PDF Editor : Convertir au format PDF Que ce soit un document, une image ou encore certains formats exotiques, BentoPDF est capable de convertir de nombreux formats de fichiers au format PDF. Ci-dessous, un extrait partiel des outils de cette catégorie. Convertir un PDF dans un autre format L'opération inverse est également possible, à savoir convertir un PDF dans un autre format. Cette section contient aussi un outil plutôt cool pour extraire toutes les images d'un document PDF. Organiser et gérer Cette section contient des outils pour diviser, fusionner ou encore supprimer des pages dans un document PDF. Vous pouvez aussi réorganiser les pages, embarquer un fichier dans un document PDF ou simplement effectuer des rotations de page. Optimiser et réparer Cette section contient des outils pour compresser et optimiser un PDF, réparer un document corrompu ou encore supprimer les protections comme un mot de passe. Sécuriser un PDF Enfin, la dernière section concerne la sécurité des documents PDF. Elle contient des outils pour chiffrer et déchiffrer un document PDF (en AES-256 bits), supprimer toutes les métadonnées (voire même tous les éléments comme les annotations, etc.) ou encore verrouiller un document. Ci-dessous, un aperçu de l'outil "Encrypt PDF" permettant de chiffrer un document PDF via l'ajout d'un mot de passe. Toutes ces fonctionnalités sont accessibles directement dans votre navigateur Web, avec un traitement effectué en local. Installation de BentoPDF avec Docker Compose Désormais, passons à l'installation de BentoPDF avec Docker (via Docker Compose). Vous devez donc disposer de Docker sur votre machine, que ce soit sous Windows, Linux ou macOS (ou votre NAS). Tutoriel - Installation de Docker sur Linux Le fichier docker-compose.yml ci-dessous est créé dans le répertoire /opt/docker-compose/bentopdf. Il est à noter que cette application ne stocke aucune donnée, il n'est donc pas nécessaire de déclarer un volume. Cet exemple est basé sur celui mis à disposition sur le site GitHub de BentoPDF. Attention, deux images Docker distinctes sont distribuées : bentopdf qui reprend l'apparence complète du site web officiel et bentopdf-simple qui reprend uniquement la partie boite à outils (cette version me semble plus pertinente pour un déploiement en local). services: bentopdf: image: bentopdf/bentopdf-simple:latest container_name: bentopdf restart: unless-stopped ports: - '8080:8080' environment: - DISABLE_IPV6=true Quelques informations supplémentaires : L'application BentoPDF sera accessible sur le port 8080 ; si vous souhaitez utiliser un autre port, changez la valeur de gauche. La variable d'environnement DISABLE_IPV6=true sert à désactiver IPv6 pour utiliser uniquement IPv4. Elle est facultative (tout dépend de votre environnement). Enregistrez et fermez le fichier. À titre d'information, voici une configuration basique pour publier BentoPDF avec le reverse proxy Traefik : services: bentopdf: image: bentopdf/bentopdf-simple:latest container_name: bentopdf restart: unless-stopped environment: - DISABLE_IPV6=true networks: - frontend labels: - "traefik.enable=true" - "traefik.docker.network=frontend" - "traefik.http.routers.bentopdf-https.rule=Host(`bentopdf.it-connectlab.fr`)" - "traefik.http.routers.bentopdf-https.entrypoints=websecure" - "traefik.http.routers.bentopdf-https.tls=true" - "traefik.http.routers.bentopdf-https.tls.certresolver=ovhcloud" - "traefik.http.services.bentopdf-https.loadbalancer.server.port=8080" - "traefik.http.routers.bentopdf-https.middlewares=crowdsec@file,tinyauth" - "tinyauth.apps.bentopdf.config.domain=bentopdf.it-connectlab.fr" networks: frontend: external: true Cette configuration protège l'application avec Tinyauth (page d'authentification) et CrowdSec (détection des attaques) en tant que middlewares Traefik. Lancez la construction du projet : docker compose up -d Votre boite à outils PDF vous attend ! Elle est accessible sur l'adresse IP de votre hôte Docker sur le port 8080, ou sur un autre port selon la configuration définie. Ensuite, vous n'avez plus qu'à commencer à jouer avec les outils. Conclusion BentoPDF est une boite à outils PDF très complète et prometteuse. Directement accessible dans votre navigateur, elle met à votre disposition un ensemble d'outils pratiques : la manipulation de documents PDF est le quotidien de nombreux utilisateurs. Vous pouvez tout à fait héberger cette application sur votre serveur et la mettre à disposition de plusieurs utilisateurs, le tout en préservant la confidentialité grâce à un traitement effectué du côté client. C'est le gros plus de cette solution et cela vous évite de déployer des applications en local sur chaque machine. Qu'en pensez-vous ? Ingénieur système et réseau, cofondateur d'IT-Connect et Microsoft MVP "Cloud and Datacenter Management". Je souhaite partager mon expérience et mes découvertes au travers de mes articles. Généraliste avec une attirance particulière pour les solutions Microsoft et le scripting. Bonne lecture. Afficher l’article complet -
Cachem Publié le 26 janvier 2026 Par Fx cachem.fr Environ 5 minutes de lecture Nous sommes en 2026 et les choses ont pas mal évolué ces derniers mois. À une certaine époque, les systèmes DIY pour NAS se comptaient sur les doigts d’une main : ce n’est plus le cas. Aujourd’hui, on trouve des solutions très abouties, avec un niveau de qualité proche du monde professionnel, comme TrueNAS Scale ou Unraid, des options intermédiaires comme OpenMediaVault (OMV), et d’autres plus accessibles et plus souples, comme CasaOS, ZimaOS ou UmbrelOS. Nous aborderons également le cas de Proxmox… Qu’est-ce que le DIY pour les NAS ? Le concept de NAS DIY (Do It Yourself) repose sur une idée simple : s’affranchir du verrouillage matériel des constructeurs (Synology, QNAP, Asustor…). Au lieu d’acheter un boîtier propriétaire, vous sélectionnez vos propres composants (boîtier, processeur, RAM, contrôleurs…) ou vous recyclez un ancien PC. Cette approche offre 2 avantages majeurs : Rapport performance/prix : pour le prix d’un NAS 4 baies du commerce équipé d’un processeur souvent limité, vous pouvez assembler une machine capable de gérer du transcodage 4K, des dizaines de conteneurs Docker, des machines virtuelles… Évolutivité : vous n’êtes plus limité par le nombre de ports, la mémoire soudée ou les choix matériels du constructeur. Votre NAS évolue avec vos besoins. À cela s’ajoute un point souvent sous-estimé : la possibilité de donner une seconde vie à un NAS qui ne reçoit plus de mises à jour… Qu’est-ce qu’un système DIY pour les NAS ? On me pose souvent la question : pourquoi parler de « système » et pas simplement de « système d’exploitation (OS) » pour NAS ? Parce qu’en 2026, un NAS moderne n’est plus seulement un serveur de partage de fichiers (SMB/NFS). C’est une plateforme qui combine trois couches complémentaires : OS : généralement Linux, il gère le matériel et le système de fichiers (ZFS, Btrfs, XFS…) ; Interface web : outil d’administration au quotidien, qui permet de gérer stockage, utilisateurs, services, mises à jour et supervision (sans passer par des lignes de commande) ; Applications : écosystème de services que vous hébergez qui était la force des fabricants historiques… mais maintenant Docker est devenu central. Les poids lourds : Performance et stockage massif Ces solutions visent d’abord la fiabilité et une gestion sérieuse du stockage. TrueNAS Scale : l’incontournable Avec ses évolutions récentes, TrueNAS Scale s’est imposé comme une référence du NAS DIY. Son point fort, c’est la protection des données grâce à ZFS (snapshots, auto-réparation, intégrité), avec une approche très “pro”. En contrepartie, ZFS reste relativement rigide : étendre un pool en ajoutant “juste un disque” n’est pas aussi souple que sur d’autres solutions. Pour exploiter ZFS dans de bonnes conditions, il est recommandé d’avoir beaucoup de mémoire vive/RAM (ECC de préférence). Si votre priorité est la pérennité et la sécurité des données, TrueNAS Scale est un excellent choix. Unraid : la flexibilité avant tout Toujours très populaire chez les particuliers, Unraid brille par sa capacité à gérer des disques hétérogènes (marques et tailles différentes) avec une grande simplicité. Son système de parité permet d’ajouter un disque facilement, au fil de l’eau. Son interface est aussi l’une des plus accessibles et sa gestion de la virtualisation (VM avec passthrough GPU) est une référence pour les configurations hybrides. Le point à intégrer dans l’équation : son modèle économique a évolué. Les mises à jour sont désormais liées à un abonnement, sauf licence à vie plus onéreuse. Cela le place face à une concurrence gratuite de plus en plus solide. Unraid reste un excellent choix pour le multimédia, l’hébergement d’applications et le recyclage de disques, à condition d’accepter le coût de la licence. L’intermédiaire OpenMediaVault est construit autour d’une base Debian, avec une philosophie simple : rester léger, stable et relativement proche de Linux. OMV tourne sur à peu près tout, y compris sur du matériel ancien. Il laisse plus de latitude pour personnaliser l’OS sous-jacent que certaines solutions plus “encadrées”. En revanche, l’interface est plus austère et demande souvent un peu plus de connaissances pour obtenir une configuration parfaitement propre (permissions, services, supervision, sauvegardes). C’est une solution cohérente pour les utilisateurs à l’aise avec Linux qui veulent un NAS sans fioritures, sur du matériel modeste. La nouvelle vague : simplicité et one-click Ici, l’objectif est clair : privilégier l’accessibilité, l’expérience utilisateur et une installation rapide. CasaOS, ZimaOS et UmbrelOS Ces systèmes (ou surcouches, selon les cas) cherchent à transformer un serveur en « cloud personnel » facile à prendre en main. Les interfaces sont modernes, visuelles et l’installation d’applications ressemble à un App Store… On déploie des services en quelques clics, ce qui les rend attractifs pour démarrer vite. La limite est structurelle : ce ne sont pas, à la base, des OS orientés « stockage avancé ». La gestion RAID, la stratégie de protection des données et les scénarios de migration/extension sont sommaires (rien à voir comparé à TrueNAS et Unraid). Ils sont donc très adaptés à un premier serveur multimédia/domotique, mais moins pertinent si vous cherchez une plateforme de stockage « sérieuse » pour des données réellement critiques. HexOS HexOS est très attendu (toujours en Bêta), car l’ambition est séduisante : proposer la puissance d’une base type TrueNAS avec une interface beaucoup plus simple. C’est une piste intéressante pour ceux qui veulent une expérience plus « grand public » sans renoncer à une base technique solide. Point important : c’est un produit payant. Son intérêt dépendra de son niveau de maturité et de la qualité de l’intégration au quotidien. L’alternative : virtualisation avec Proxmox Techniquement, Proxmox VE n’est pas un OS de NAS : c’est un hyperviseur. Mais en 2026, c’est la base de nombreuses installations homelab. Le principe est simple : vous installez Proxmox sur le matériel (bare metal), puis vous déployez votre NAS (TrueNAS, OMV…) dans une machine virtuelle et vos autres services dans d’autres VM ou conteneurs. L’intérêt ici, c’est que vous séparez les rôles. Vous facilitez les sauvegardes complètes (snapshots, export) et vous rendez l’infrastructure plus résiliente. Si un service tombe, le reste continue de tourner et vous pouvez restaurer proprement. Cependant, c’est une approche plutôt réservée aux utilisateurs avancés. Elle demande une bonne maîtrise des notions de stockage (pass-through, contrôleurs, performances, sécurité des données). Que choisir en 2026 ? Le choix ne dépend plus uniquement des fonctionnalités (Docker est devenu un standard), mais de votre priorité? Vous voulez : Protéger vos données avant tout : TrueNAS Scale Recycler des disques variés et évoluer facilement : Unraid Une solution simple, légère, proche de Linux : OMV Une belle interface et démarrage rapide : CasaOS ou ZimaOS Un homelab complet et une infra modulaire : Proxmox Certains diront que le NAS DIY est à son apogée. De mon côté, je le vois plutôt comme une étape : les outils se simplifient, les standards se consolident et le niveau de finition continue de monter. Reste à choisir l’approche qui correspond à vos contraintes… et à votre tolérance à la complexité. Afficher l’article complet
-
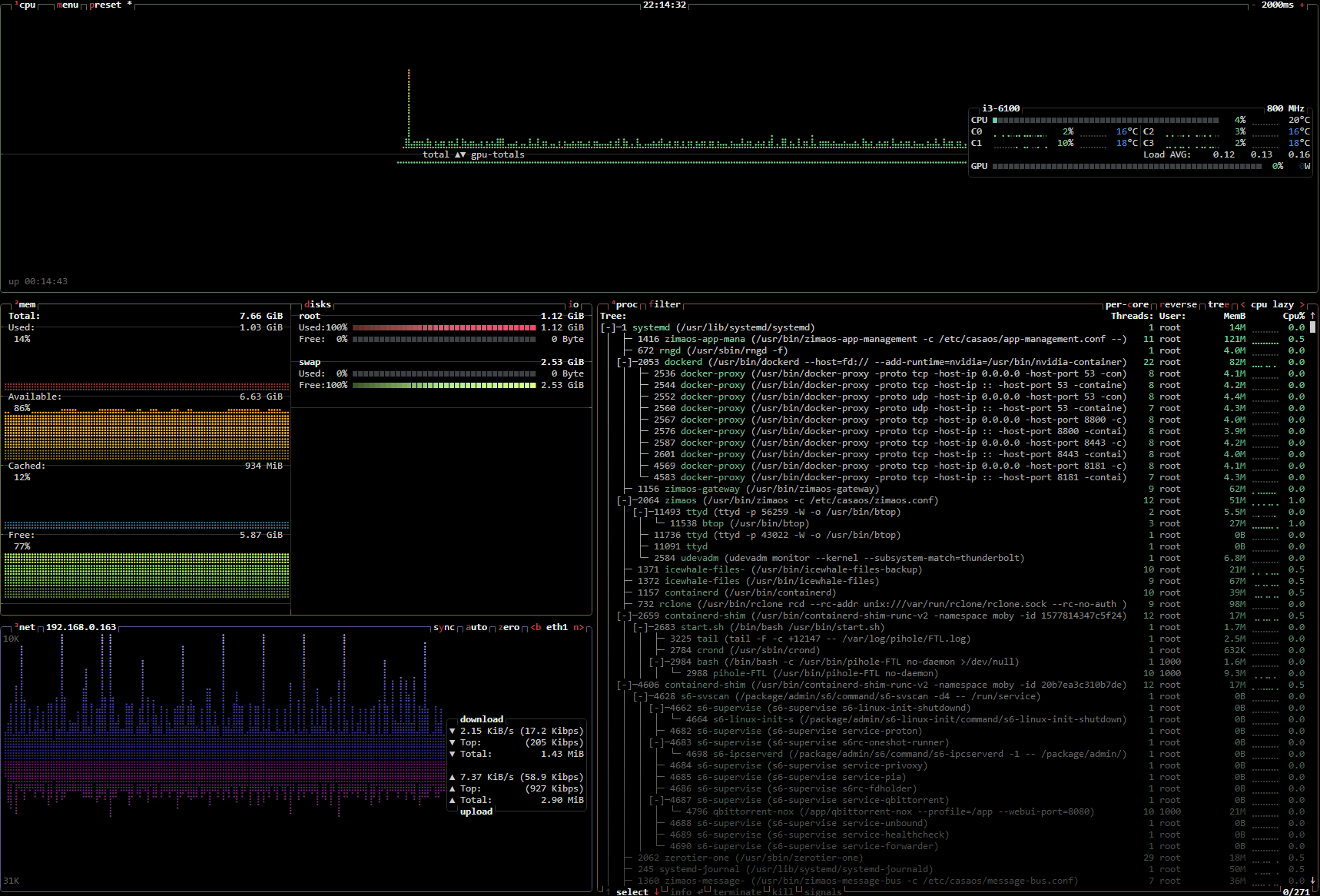
Up and Clear | Reborn upandclear.org Environ 5 minutes de lecture Après avoir mis de côté UNRAiD, dont je me suis lassé, j’ai passé le LincStation N1 sous TrueNAS. Cet OS ne m’apporte rien d’autre que la gestion simplifiée des RAIDs via une WebUI (parce que bon… mdadm… c’est chiant). Enfin je ne cherche pas à utiliser l’OS pour être précis, je ne peux donc pas dire qu’il est nul ou top. M’en tape. Les autres machines, tout aussi peu puissantes que le N1 sont sous Archlinux et Ubuntu. Arch parce que j’aime bien me demander chaque jour si une MàJ va plomber le serveur et comment je vais m’en dépatouiller (et c’est accessoirement mon desktop). Ubuntu, pour changer de Debian, parce que j’ai quand même besoin d’un truc stable dans ma vie de geek. N’utilisant quasi plus de VM/LXC depuis l’avènement de Docker, je n’ai plus de ProxMox. Du coup, je shunte Ubuntu au profit d’une distribution basée sur Debian : ZimaOS ! Jai passé hier l’ensemble de mes services « utiles » sur TrueNAS pour libérer cette machine pour ce test. Avertissement : c’est asiat’. Alors pour les complotistes américains peureux bas du front (rayez ou non les mentions inutiles), n’allez pas plus loin. Je n’ai absolument pas fait de RE pour savoir s’ils ont mis des backdoors. « Mais » CVE-2026-21891 (non encore relayée sur GitHub) / discussion Reddit et si j’ai pas sniffé le trafic, mon DNS ne fait rien ressortir d’extraordinaire. La machine ping même pas Baidu, contrairement à la majorité des objets IoT qui s’assurent d’être connectés à Internet en pingant le de Google chinoix (oui, eux aussi ont leur GAFAM BATX). J’ai découvert cet OS par hasard, quand je cherchais des infos sur des boards de serveurs. J’ai d’ailleurs commencé par découvrir CasaOS, dont j’étais pas fans. Ça faisait un peu Docker in Docker. Pour moi c’est plus à voir comme une alternative à YunoHost (très bon projet pour ceux qui sortent d’une grotte et ne connaissent pas). Même ressenti pour Cosmos d’ailleurs. ZimaOS est développé pour leurs NAS ZimaCube mais on peut l’installer partout. Ils font eux-mêmes la comparaison entre ZimaOS et CasaOS, en gros : C’est un UNRAiD like, avec une interface plus moderne (avis 100% subjectif), avec des clients à la Synology pour Windows, macOS, Linux (AUR), iOS et Android, avec une documentation bien faite sans tomber dans un Wikipedia comme on peut le voir chez certains concurrents, un GitHub et donc la possibilité d’ouvrir des issues (ce qui est bien plus pratique qu’un forum), Ça s’installe en 2-2 avec une clé USB (iso de 1.3Go) créée avec Balena et se gère uniquement via la WebUI. J’utilise la version gratuite. Et il faut activer le Mode Développeur notamment pour désactiver l’indexation du contenu avec leur « IA » (pour faciliter la recherche) et autoriser SSH. Première vraie configuration à faire, mon stockage. De mémoire j’ai que 2 disques dans ce PC mais la version gratuite permet d’en gérer 4 en RAID. Et la version payante coûte 29$ (« à vie »). Comme j’ai qu’un SSD en sus de celui de l’OS, je me contente de le formater et ça l’ajoute bien ensuite en stockage. Ce que je vois d’ailleurs avec le widget de la dashboard, qui passe à 718Go de stockage. Et donc, en standard, ZimaOS intègre un explorateur de fichiers, un outil de backup (depuis ou vers le NAS), un gestionnaire de VM et un PairDrop (je vois la machine sous Windows mais pas mon Arch, faudra que je trouve pourquoi). Depuis un client (Linux/iOS), on peut parcourir les fichiers du serveur et faire du backup. Notamment de photos depuis l’iPhone (arrière plan ou non). On peut ajouter des liens externes à la dashboard, ce qui est une très bonne idée et pourrait m’inciter à me passer de mon brave Heimdall qui m’accompagne depuis maintenant des années… Et nous terminons évidemment avec le fameux AppStore et ses 372 applications (Docker) « prêtes à installer » au moment de cet article. Rien de comparable avec UNRAiD, je vous l’accorde. Mais ici, ça s’installe en 1 clic. Et on peut ajouter des dépôts et doubler, au moins, le nombre d’applications du store. Tout comme il est possible d’installer une app via la WebUI si on elle n’est pas dans le Store et qu’on n’est vraiment pas à l’aise en console. On peut tout à fait utiliser Docker en console ou via Komodo, Arcane, Dockge, Portainer/what ever. Et ça marche « out of the box » dans ce cas, il n’y a rien à adapter pour l’OS. À noter que par défaut, les applications installées via l’AppStore sont dans /DATA, sur le disque système. root@ZimaOS:~ ➜ # tree /DATA/ /DATA/ ├── AppData │ └── pihole │ └── etc │ └── pihole │ ├── adlists.list │ ├── cli_pw │ ├── config_backups │ │ └── pihole.toml.1 │ ├── dhcp.leases │ ├── dnsmasq.conf │ ├── gravity.db │ ├── gravity_backups │ │ └── gravity.db.1 │ ├── gravity_old.db │ ├── hosts │ │ └── custom.list │ ├── listsCache │ │ ├── list.1.raw.githubusercontent.com.domains │ │ ├── list.1.raw.githubusercontent.com.domains.etag │ │ └── list.1.raw.githubusercontent.com.domains.sha1 │ ├── logrotate │ ├── migration_backup │ │ └── adlists.list │ ├── pihole-FTL.db │ ├── pihole-FTL.db-shm │ ├── pihole-FTL.db-wal │ ├── pihole.toml │ ├── tls.crt │ ├── tls.pem │ ├── tls_ca.crt │ └── versions ├── Backup ├── Documents ├── Downloads │ └── ISO ├── Gallery ├── Media │ ├── Movies │ ├── Music │ └── TV Shows └── lost+found Comme ça se voit au-dessus, j’ai installé Pi-Hole depuis l’AppStore pour tester. Faut juste cliquer pour installer. Pratique : en cas d’ajout de disques, on peut migrer les données facilement Même si ZimaOS est basé sur Debian, c’est propriétaire et on ne peut pas utiliser Apt pour y installer ce qu’on veut. C’est une sécurité également, histoire de ne pas mettre en vrac l’OS (ce qu’on est nombreux à avoir fait avec Proxmox hein… mentez pas !!). Ceci dit ils ont prévu le coup. Ceci dit, leur OS embarque déjà bon nombre d’utilitaires tels que ncdu, jq, rclone… Dans l’idéal, j’aimerais un dash qui permet de mieux intégrer quelques applications comme le font Heimdall, Homarr, Organizr etc. Aperçu du client iOS Avec le recul de cet article, je perçois ZimaOS comme un DSM de Synology, enfin plutôt un Xpenology vu qu’on peut l’installer où on veut, avec un peu de combo d’UNRAiD et cousins. Enfin tous ces OS se ressemblent mais ZimaOS serait un peu le « macOS » du groupe, à vouloir proposer une expérience très esthétique, complète (Docker natif ou magasin d’applications), pratique (outils intégrés, y compris pour périphériques) et répondant AMHA à la plupart des besoins. Bien que propriétaire, contrairement à CasaOS qui est open source mais n’est qu’une surcouche. Je pense le faire tourner quelques temps en parallèle de TrueNAS voir remplacer ce dernier. Et j’avais oublié, ça embarque aussi Btop++ pour afficher des stats temps réel. Afficher l’article complet

-
Linux PatchMon : surveillez les mises à jour des machines Linux - IT Connect
Ldfa a posté un sujet dans Mon Wallabag
IT-Connect Publié le 12 janvier 2026 Par Florian BURNEL it-connect.fr Environ 12 minutes de lecture PatchMon est une solution open source de Patch Monitoring pour les serveurs Linux, qu'ils soient sous Debian, Ubuntu, Alma Linux ou encore Red Hat Enterprise Linux (RHEL). L'objectif principal de PatchMon est le suivant : vous offrir une vue d'ensemble sur l'état des mises à jour sur vos machines Linux. Ainsi, vous pouvez identifier facilement les machines sur lesquelles des mises à jour de paquets sont en attente, avec une mise en évidence des mises à jour de sécurité. Les machines sous Linux, au même titre que celles sous Windows, reçoivent des mises à jour. D'une part, il y a les mises à jour du système et du noyau, et d'autre part, les mises à jour des paquets installés (du paquet de la simple bibliothèque à celui d'un service utilisé en production). Comment suivre la disponibilité des mises à jour ? Si l'on prend l'exemple de machines sous Debian, exécuter les commandes apt update et apt upgrade manuellement n'est pas une solution viable et efficace. C'est là qu'un outil comme PatchMon apporte une valeur ajoutée : son tableau de bord affiche l'état des mises à jour de l'ensemble de vos machines Linux. Son fonctionnement repose sur l'installation d'un agent sur les machines à monitorer. À la clé : Un inventaire de vos machines (avec la répartition par type d'OS) Un aperçu du niveau de mises à jour de vos machines (à jour, en attente de mise à jour, en attente d'un redémarrage) Une visibilité sur le type de mises à jour en attente (distinction entre mise à jour standard et correctif de sécurité) Une tendance globale dans le temps Des statistiques globales sur l'ensemble de votre SI L'état de la réception des données de la part des agents Au-delà d'offrir une vue par machine, PatchMon offre aussi une vue par paquet : pratique pour identifier les machines sur lesquelles est installé tel ou tel paquet. Il référence aussi la liste des dépôts (repos) configurés sur vos machines. Précision importante : la version actuelle de PatchMon ne permet pas de gérer la mise à jour des paquets. Nous sommes donc dans une approche de monitoring, sans qu'il soit possible d'appliquer les mises à jour en attente. Mais les choses vont évoluer à l'avenir : la feuille de route évoque des fonctionnalités croustillantes, dont celle-ci. PatchMon est un projet qui a énormément progressé en quelques mois. L'intégration avec Docker pour remonter les informations sur les conteneurs, les images, etc... est actuellement en bêta, tandis que d'autres intégrations sont en préparation (Proxmox VE, etc.). C'est un projet à suivre en 2026 ! GitHub - PatchMon Installation du serveur PatchMon L'installation de PatchMon sera réalisée sur un serveur où Docker a été installé au préalable. Nous utiliserons un fichier Docker Compose car la stack PatchMon repose sur plusieurs conteneurs : Base de données avec PostgreSQL, Cache objet avec Redis, Backend de PatchMon, Frontend de PatchMon Créer un dossier pour le projet Docker Comme à mon habitude, j'ai créé un dossier dédié à ce projet sur mon serveur afin d'isoler les données associées à PatchMon. Le dossier suivant a été créé : /opt/docker-compose/patchmon Par la suite, trois sous-dossiers seront créés dans ce dossier (vous pouvez les créer manuellement ou laisser Docker procéder) : /opt/docker-compose/patchmon | |___ agent_files |___ postgres_data |___ redis_data Note : un quatrième dossier nommé branding_assets peut être ajouté si vous souhaitez déposer des éléments spécifiques pour personnaliser l'apparence de l'interface. Par exemple : remplacer le logo PatchMon par celui de votre entreprise. Générer 3 mots de passe Avant de créer le fichier Docker Compose, je vous invite à générer trois mots de passe qu'il sera nécessaire d'insérer dans ce fichier. Ils seront utilisés pour personnaliser les mots de passe de PostgreSQL et Redis, et pour le secret JWT. Voici à titre d'information les trois valeurs utilisées pour ce tutoriel et obtenues via la même commande que vous pouvez lancer sur votre serveur. # Mot de passe de la base de données openssl rand -hex 64 eb2b687f514ddcd25226de40437a59a0f9fbac5ffe72fda2e5e6d11b31e2b9e99c4aeb6944f73c37f76ba175082821a69fb625d1b080dac7df66a7ff1ea967af # Mot de passe Redis openssl rand -hex 64 0ba2b3084b93fa7bfb49452c23bea7a50c2772a9c1e3e83437db283ea37874e59febd0e09d77e1579348d2fb10cf46e7a7de17656bc7312099622fada8f42f23 # Secret JWT openssl rand -hex 64 e0b7f1ad9bd73bd271b3d161fb013c6a90e5de48e8ed4b0cb80d9717f4cb1886470671f527565158c37a1c78db92614287844eb95135abaee50ac60a0539a2cb Créer le fichier Docker Compose Voici le fichier docker-compose.yml que vous devez créer à la racine de votre projet PatchMon. Vous devez le personnaliser de façon à insérer vos mots de passe. J'ai mis des couleurs distinctes sur les trois valeurs pour que vous puissiez vous y retrouver. Cette configuration s'appuie sur la version disponible sur le GitHub officiel du projet. name: patchmon services: database: image: postgres:17-alpine restart: unless-stopped environment: POSTGRES_DB: patchmon_db POSTGRES_USER: patchmon_user POSTGRES_PASSWORD: eb2b687f514ddcd25226de40437a59a0f9fbac5ffe72fda2e5e6d11b31e2b9e99c4aeb6944f73c37f76ba175082821a69fb625d1b080dac7df66a7ff1ea967af volumes: - ./postgres_data:/var/lib/postgresql/data networks: - patchmon-internal healthcheck: test: ["CMD-SHELL", "pg_isready -U patchmon_user -d patchmon_db"] interval: 3s timeout: 5s retries: 7 redis: image: redis:7-alpine restart: unless-stopped command: redis-server --requirepass 0ba2b3084b93fa7bfb49452c23bea7a50c2772a9c1e3e83437db283ea37874e59febd0e09d77e1579348d2fb10cf46e7a7de17656bc7312099622fada8f42f23 volumes: - ./redis_data:/data networks: - patchmon-internal healthcheck: test: ["CMD", "redis-cli", "--no-auth-warning", "-a", "0ba2b3084b93fa7bfb49452c23bea7a50c2772a9c1e3e83437db283ea37874e59febd0e09d77e1579348d2fb10cf46e7a7de17656bc7312099622fada8f42f23", "ping"] interval: 3s timeout: 5s retries: 7 backend: image: ghcr.io/patchmon/patchmon-backend:latest restart: unless-stopped # See PatchMon Docker README for additional environment variables and configuration instructions environment: LOG_LEVEL: info DATABASE_URL: postgresql://patchmon_user:eb2b687f514ddcd25226de40437a59a0f9fbac5ffe72fda2e5e6d11b31e2b9e99c4aeb6944f73c37f76ba175082821a69fb625d1b080dac7df66a7ff1ea967af@database:5432/patchmon_db JWT_SECRET: e0b7f1ad9bd73bd271b3d161fb013c6a90e5de48e8ed4b0cb80d9717f4cb1886470671f527565158c37a1c78db92614287844eb95135abaee50ac60a0539a2cb SERVER_PROTOCOL: http SERVER_HOST: 192.168.10.200 SERVER_PORT: 3000 CORS_ORIGIN: http://192.168.10.200:3000 # Database Connection Pool Configuration (Prisma) DB_CONNECTION_LIMIT: 30 DB_POOL_TIMEOUT: 20 DB_CONNECT_TIMEOUT: 10 DB_IDLE_TIMEOUT: 300 DB_MAX_LIFETIME: 1800 # Rate Limiting (times in milliseconds) RATE_LIMIT_WINDOW_MS: 900000 RATE_LIMIT_MAX: 5000 AUTH_RATE_LIMIT_WINDOW_MS: 600000 AUTH_RATE_LIMIT_MAX: 500 AGENT_RATE_LIMIT_WINDOW_MS: 60000 AGENT_RATE_LIMIT_MAX: 1000 # Redis Configuration REDIS_HOST: redis REDIS_PORT: 6379 REDIS_PASSWORD: 0ba2b3084b93fa7bfb49452c23bea7a50c2772a9c1e3e83437db283ea37874e59febd0e09d77e1579348d2fb10cf46e7a7de17656bc7312099622fada8f42f23 REDIS_DB: 0 volumes: - ./agent_files:/app/agents networks: - patchmon-internal depends_on: database: condition: service_healthy redis: condition: service_healthy frontend: image: ghcr.io/patchmon/patchmon-frontend:latest restart: unless-stopped ports: - "3000:3000" networks: - patchmon-internal depends_on: backend: condition: service_healthy volumes: postgres_data: redis_data: agent_files: networks: patchmon-internal: driver: bridge Dans ce fichier, vous pourrez constater que : Les conteneurs seront connectés sur le même réseau Docker intitulé patchmon-internal, L'application est exposée sur le port 3000 via le conteneur frontend, Des dépendances sont définies entre certains conteneurs via les instructions depends_on. Au-delà des mots de passe et secrets, vous devez ajuster plusieurs variables pour éviter d'avoir une erreur de sécurité lors de la première connexion : SERVER_PROTOCOL: http : http ou https, selon la méthode d'accès. SERVER_HOST: 192.168.10.200 : le nom public du serveur, mettez l'IP ou le nom. SERVER_PORT: 3000 : le port d'accès, doit être cohérent vis-à-vis du port exposé sur le frontend. CORS_ORIGIN: http://192.168.10.200:3000 : ajustez cette valeur pour qu'elle représente l'adresse publique sur laquelle sera joignable PatchMon. Autrement dit, n'indiquez pas localhost ou 127.0.0.1. Ici, je précise l'adresse IP de mon hôte Docker car les échanges seront uniquement sur le réseau local. Ici, nous effectuons un accès en HTTP à l'application PatchMon. Pour la production, il est bien entendu recommandé d'associer un reverse proxy pour publier l'application en HTTPS, avec un certificat TLS. Pour aller plus loin, il y a d'autres variables d'environnement disponibles : référez-vous à cette page de la documentation. Enregistrez et fermez le fichier. Initialiser le projet Docker Compose Désormais, vous pouvez initialiser le projet Docker. Les images seront téléchargées, le réseau créé, tout comme les différents conteneurs. Patientez un instant. docker compose up -d Si vous avez une erreur, consultez les journaux : docker compose logs Il est possible que le conteneur backend refuse de démarrer à cause d'une erreur de permissions sur le dossier agent_files. Vous pouvez corriger cette erreur via la commande suivante : sudo chown -R 1000:1000 /opt/docker-compose/patchmon/agent_files Première connexion à PatchMon Ouvrez votre navigateur web et tentez d'accéder à l'interface de PatchMon, en saisissant son adresse. Saisissez l'adresse associée au paramètre CORS_ORIGIN. Pour ma part, ce sera donc : http://192.168.10.200:3000. Vous devez commencer par créer un premier compte utilisateur correspondant à l'administrateur de la plateforme PatchMon. Voilà, bienvenue sur votre instance PatchMon ! Je vous encourage à prendre le temps de parcourir les paramètres, en cliquant sur le bouton "Settings" en bas à gauche. Il y a plusieurs sections, que ce soit pour gérer les comptes utilisateurs, les rôles, votre profil, ou encore les groupes d'hôtes. Par exemple, vous pouvez activer le MFA sur votre compte administrateur. Cliquez sur "URL Config" dans la liste pour vérifier que l'adresse du serveur est bien prise en charge. C'est important de le vérifier, même si ça doit déjà être correct grâce aux variables SERVER_* configurées précédemment. Cette page affiche l'adresse qui sera utilisée par les clients pour contacter le serveur PatchMon. Si c'est incorrect, vous allez rencontrer des problèmes par la suite... Une fois que vous avez terminé votre petit tour de l'interface PatchMon, passez à la suite : le déploiement d'un premier agent. Déployer un agent PatchMon sur Linux Pour ajouter manuellement un nouvel hôte à PatchMon, vous devez déployer un nouvel agent. À partir de la section "Hosts", cliquez sur le bouton "Add host" (ou directement sur le "+" dans le menu de gauche). Pour le moment, la liste des hôtes est vide. Donnez un nom à cette machine, en toute logique le nom du serveur cible. Il est aussi possible : d'ajouter l'hôte à un groupe d'hôtes, mais par défaut il n'y a pas de groupe. C'est modifiable par la suite. d'activer une intégration, soit pour le moment l'intégration avec Docker (d'autres sont en cours de développement). Cliquez sur le bouton "Create Host" pour valider. Une fenêtre va s'afficher à l'écran. Elle indique la commande à copier-coller pour automatiser l'installation de l'agent PatchMon et l'inscription auprès du serveur. Pour ma part, la commande à exécuter est la suivante : curl -s http://192.168.10.200:3000/api/v1/hosts/install -H "X-API-ID: patchmon_2a08e8a52f0ae9fb" -H "X-API-KEY: 5bbc4e017f9c4a0ca8e485d11fd911e85e4768a38f5e832be1826d68532714e1" | sh Si vous ne lancez pas la commande directement en tant que root, vous devez ajouter sudo juste devant sh dans la seconde partie de la commande. L'opération est effectuée en quelques secondes. Les informations dans la console permettent d'avoir un aperçu des actions effectuées. Vous devriez voir passer deux lignes indiquant que les identifiants sont valides et que la connexion au serveur a été effectuée avec succès. Quelques précisions : Les identifiants de connexion à l'API sont stockés dans le fichier /etc/patchmon/credentials.yml. Le fichier de configuration, comprenant notamment l'adresse vers le serveur, est le fichier suivant : /etc/patchmon/config.yml. Le fichier journal de l'agent PatchMon est le suivant : /etc/patchmon/logs/patchmon-agent.log Suite à l'installation, l'hôte apparait bien sur l'interface de PatchMon. Vous pouvez actualiser les données en cliquant sur le bouton en haut à droite. Sur cette machine, on voit bien qu'il y a un retard considérable au niveau des mises à jour ! Note : l'agent PatchMon est équipé d'une fonction de mise à jour automatique activée par défaut. PatchMon collecte des informations générales sur la machine, en particulier pour le réseau, le système et le stockage. Vous pouvez naviguer entre les différents onglets : Sur le même principe, vous pouvez ajouter d'autres hôtes. La vue globale offrira alors une vue synthétique sur les hôtes enregistrés. Les commandes pour gérer l'agent PatchMon Voici quelques commandes utiles pour administrer l'agent PatchMon sur un serveur. Tester la connexion : patchmon-agent ping --------------------------------- ✅ API credentials are valid ✅ Connectivity test successful Lancer une synchronisation depuis l'agent : patchmon-agent report Afficher l'état de l'agent : patchmon-agent diagnostics --------------------------------- ✅ API credentials are valid ✅ Connectivity test successful root@srv-haproxy:~# patchmon-agent diagnostics PatchMon Agent Diagnostics v1.3.7 System Information: OS: Debian GNU/Linux 12 (bookworm) Architecture: amd64 Kernel: 6.1.0-25-amd64 Hostname: srv-haproxy Machine ID: 7cf53fba-b483-4621-9d3a-461833b6c214 Agent Information: Version: 1.3.7 Config File: /etc/patchmon/config.yml Credentials File: /etc/patchmon/credentials.yml Log File: /etc/patchmon/logs/patchmon-agent.log Log Level: info Configuration Status: ✅ Config file exists ✅ Credentials file exists Network Connectivity & API Credentials: Server URL: http://192.168.10.200:3000 ✅ Server is reachable ✅ API is reachable and credentials are valid Last 10 log entries: time="2026-01-08T11:06:57" level=info msg="Reboot status check completed" installed_kernel=6.1.0-25-amd64 needs_reboot=false reason= running_kernel=6.1.0-25-amd64 time="2026-01-08T11:06:57" level=info msg="Collecting package information..." time="2026-01-08T11:07:01" level=info msg="Found packages" count=360 time="2026-01-08T11:07:01" level=info msg="Collecting repository information..." time="2026-01-08T11:07:01" level=info msg="Found repositories" count=6 time="2026-01-08T11:07:01" level=info msg="Sending report to PatchMon server..." time="2026-01-08T11:07:02" level=info msg="Report sent successfully" time="2026-01-08T11:07:02" level=info msg="Processed packages" count=360 time="2026-01-08T11:07:07" level=info msg="Checking for agent updates..." time="2026-01-08T11:07:07" level=info msg="Agent is up to date" version=1.3.7 Afficher l'état du service : systemctl status patchmon-agent Afficher les logs de l'agent PatchMon : journalctl -u patchmon-agent -f Redémarrer le service : systemctl restart patchmon-agent Le monitoring de Docker avec PatchMon Si vous installez l'agent PatchMon sur une machine équipée de Docker et que vous activez l'intégration Docker, vous pourrez alors suivre l'état de vos conteneurs depuis l'interface de PatchMon. Toujours dans l'esprit monitoring, l'interface affiche l'état des conteneurs, la liste des images, des réseaux et des volumes. Pour le cas des images, ce qui est cool, c'est que PatchMon indique s'il y a une mise à jour disponible ou non, ainsi que d'autres informations (nom, tag, source, etc.). J'ai constaté qu'au début les images remontent toutes en "Up to date" (à jour), mais que l'état réel apparaît un peu plus tard. Ci-dessous, un exemple. Au niveau de chaque hôte, vous pouvez activer ou désactiver des intégrations, que l'on peut considérer comme des modules, via l'onglet "Integrations". Le site de PatchMon laisse entendre que d'autres intégrations arriveront par la suite : WordPress, Apache, Ubiquiti, Proxmox, Azure ou encore Google (vous pouvez voter d'ailleurs). Conclusion Si vous gérez déjà vos mises à jour de façon automatisée (avec Ansible, par exemple), le fait d'utiliser PatchMon ajoute une couche de monitoring intéressante pour savoir quand il est nécessaire d'agir sur tel ou tel serveur. C'est vrai pour un Home Lab et pour une petite infrastructure où PatchMon peut se faire une place pour apporter une meilleure visibilité. La solution PatchMon est jeune, mais elle évolue vite, et j'ai le sentiment qu'elle va progresser dans la bonne direction. Une communauté d'une dizaine de personnes contribue déjà au développement de la solution et le projet semble bien reçu ! Maintenant, nous attendons avec impatience la gestion des mises à jour et, pourquoi pas, à terme, la prise en charge des machines sous Windows. FAQ PatchMon Qu'est-ce que PatchMon ? PatchMon est un outil open source de surveillance des correctifs (patch monitoring) pour les systèmes Linux. Il offre un tableau de bord centralisé permettant de visualiser l'état des mises à jour (paquets installés, mises à jour de sécurité manquantes, etc.) sur l'ensemble de vos serveurs, sans avoir à s'y connecter individuellement. Il supporte aussi la découverte des conteneurs Docker et des conteneurs LXC sur les hôtes Proxmox VE. Comment fonctionne la communication entre mes serveurs et PatchMon ? L'architecture de PatchMon repose sur un modèle "agent-serveur". Un agent codé en Go est installé sur chaque machine Linux à surveiller. Cet agent initie la connexion vers votre serveur PatchMon (il est donc question d'une communication sortante uniquement). Vous n'avez pas besoin d'ouvrir de ports entrants sur vos serveurs surveillés, ce qui est un bon point pour la sécurité. Comment déployer en masse l'agent PatchMon ? La façon la plus adaptée de déployer l'agent PatchMon en masse sur un ensemble de machines Linux me semble être l'utilisation d'un playbook Ansible. D'ailleurs, au sujet d'Ansible, sachez qu'il y a un plugin d'inventaire dynamique PatchMon pour Ansible (voir cette page). PatchMon peut-il découvrir les conteneurs LXC de Proxmox VE ? Oui, PatchMon dispose d'une fonction nommée "Proxmox Auto-Enrollment" pour découvrir et inscrire automatiquement les conteneurs LXC des hôtes Proxmox VE. Le script de découverte tourne directement sur l'hôte Proxmox VE. Cette fonctionnalité est décrite sur cette page de la documentation. Ingénieur système et réseau, cofondateur d'IT-Connect et Microsoft MVP "Cloud and Datacenter Management". Je souhaite partager mon expérience et mes découvertes au travers de mes articles. Généraliste avec une attirance particulière pour les solutions Microsoft et le scripting. Bonne lecture. Afficher l’article complet -
Radio Intercept - Un dashboard SIGINT pour votre clé RTL-SDR
Ldfa a posté un sujet dans Mon Wallabag
Le site de Korben Publié le 2 janvier 2026 Par Korben korben.info Environ 2 minutes de lecture Si vous avez une clé USB RTL-SDR qui traîne dans un tiroir et que vous vous demandez ce que vous pourriez bien en faire, j'ai peut-être trouvé le projet qui va vous occuper pendant quelques soirées. Ça s'appelle Intercept , et c'est un dashboard web qui regroupe les outils de réception radio les plus courants dans une seule interface. Comme ça, au lieu de jongler entre multimon-ng pour décoder les pagers, rtl_433 pour les capteurs météo, dump1090 pour tracker les avions... vous avez tout ça dans une seule interface Flask accessible directement sur votre navigateur. L'installation se fait via pip après un clone du repo, et certaines fonctions nécessitent des privilèges élevés (sudo) pour accéder aux interfaces réseau : git clone https://github.com/smittix/intercept.git cd intercept pip install -r requirements.txt Et pour le lancer : sudo python3 intercept.py Le truc tourne en local sur le port 5050 et agrège les données de six modules différents. Côté signaux, on peut décoder les protocoles POCSAG et FLEX (les pagers qu'utilisent encore certains services d'urgence, notamment aux États-Unis et au Royaume-Uni), surveiller la bande 433MHz où communiquent les stations météo et divers capteurs IoT. Pour le tracking, y'a un module ADS-B qui affiche les avions sur une carte OpenStreetMap avec leur trace historique, et un autre pour les satellites qui prédit les prochains passages au-dessus de votre position. Là où ça devient plus... disons "sensible", c'est avec les modules WiFi et Bluetooth. Le premier peut passer votre carte en mode monitor pour analyser les réseaux environnants et, si un client se reconnecte au bon moment, capturer des handshakes WPA. Le second scanne les appareils Bluetooth à portée. Évidemment, selon les lois de votre pays, ce genre d'analyse peut être encadré voire interdit sur des équipements tiers donc renseignez vous bien avant d'aller en prison bêtement. Le projet affiche d'ailleurs un gros disclaimer au lancement. Techniquement, c'est du Python avec Flask pour le backend, Leaflet.js pour les cartes, et des Server-Sent Events pour le streaming en temps réel. L'interface propose un thème sombre ou clair, des alertes sonores configurables, et l'export des données en CSV ou JSON. Y'a même des raccourcis clavier pour les power users. Pour faire tourner le bazar, il vous faut un dongle RTL-SDR compatible (les modèles à base de RTL2832U font l'affaire), une carte WiFi supportant le mode monitor si vous voulez cette fonction, et les dépendances habituelles : rtl-sdr, multimon-ng, rtl_433, dump1090, aircrack-ng pour le WiFi et BlueZ pour le Bluetooth . Le projet est sous licence MIT, développé par smittix avec l'aide de quelques contributeurs. Ça me rappelle un peu l'époque où on bidouillait avec les femtocells pour intercepter les communications , sauf qu'ici c'est packagé proprement et ça ne nécessite pas de souder quoi que ce soit. Si vous cherchez un projet pour apprendre les bases de l'intelligence des signaux radio ou juste pour voir ce qui se passe dans les ondes autour de vous, c'est un excellent point de départ. Par contre, je vous recommande vraiment de lire les lois de votre pays sur l'interception des communications avant de brancher quoi que ce soit... Afficher l’article complet -
Linux Glances : superviser votre système Linux facilement - IT-Connect
Ldfa a posté un sujet dans Mon Wallabag
www.it-connect.fr Publié le 11 décembre 2025 it-connect.fr Environ 8 minutes de lecture La supervision d'un système Linux directement depuis le Terminal, c'est possible avec Glances. Un outil open source qui va vous faire oublier les commandes top et htop, bien qu'elles restent classiques pour tout administrateur système. Glances propose une approche modernisée avec des options supplémentaires pour visualiser l'état de santé de vos machines en un clin d'œil. Glances est particulièrement pertinent pour : Consulter rapidement l'état général d'un système avec une seule et unique commande, Diagnostiquer un goulot d'étranglement (CPU, I/O disque ou RAM) sur un serveur de production, Mettre en place une surveillance légère via une interface web sur une machine dépourvue d'interface graphique. <iframe class="iframe_youtube" src="https://www.youtube.com/embed/-jg9wvVqBHk" title="Glances : la supervision système facile dans le Terminal" frameborder="0" referrerpolicy="strict-origin-when-cross-origin" allowfullscreen="allowfullscreen">[embedded content]</iframe> Glances est un outil de supervision système libre développé en langage Python. Il a été créé il y a plus de 10 ans par un Français : Nicolas Hennion, connu sous le pseudo de Nicolargo. Sa particularité : il affiche un état complet d'un système directement dans le terminal, ce qui est particulièrement intéressant sur les serveurs où les interactions s'effectuent uniquement en ligne de commande. Site officiel de Glances GitHub de Glances Même si je le présente ici dans le contexte de Linux, Glances présente la particularité de fonctionner sur de multiples plateformes : GNU/Linux, macOS, Windows et FreeBSD. Il prend en charge trois modes d'exécution différents : Standalone : exécution locale classique dans le terminal. Client/Serveur : surveillance à distance. Web Server : affichage des métriques directement via votre navigateur web. L'objectif de Glances n'est pas de remplacer un outil de supervision complet, où vous aurez des alertes et un historique, mais d'offrir un tableau de bord complet et immédiat. Pour autant, Glances peut communiquer avec d'autres applications grâce à son API. Il prend aussi l'export des données via InfluxDB ou vers un simple fichier CSV. On peut aussi nommer la possibilité d'exporter vers Prometheus pour ensuite afficher les informations avec Grafana. Puisque Glances est développé en Python, il a besoin de Python. Pour l'installer, il y a plusieurs méthodes envisageables : installer directement le paquet glances (et ses dépendances) via apt sur Debian / Ubuntu, ou encore directement avec pipx. Il est dans la majorité des dépôts officiels des distributions Linux. C'est la méthode la plus simple pour une intégration rapide, bien que la version distribuée ne soit pas nécessairement la dernière. Par exemple, actuellement, Debian 13 distribue la version 4.3.1 alors que la plus récente est la 4.4.1. Pour installer Glances sur Debian ou Ubuntu : sudo apt update sudo apt install glances Comme le montre l'image ci-dessous, de nombreuses dépendances Python seront aussi installées. Une fois tous les paquets installés, vous pouvez profiter de Glances ! Pour bénéficier des dernières fonctionnalités, l'installation avec Pipx directement via Python est recommandée. Vous devez, au préalable, installer Python sur votre machine et préparer votre environnement. # Installation de Glances avec pipx (toutes les fonctionnalités activées) pipx install 'glances[all]' # Installation de Glances avec pip (toutes les fonctionnalités activées) pip install --user glances[all] # Installation de base de Glances + interface web pipx install --user 'glances[web]' Vous pouvez retrouver le détail des fonctionnalités sur cette page du site PyPi. Des images Docker de Glances sont disponibles sur le Docker Hub. C'est plutôt intéressant car cela évite d'installer Glances et toutes ses dépendances sur la machine si vous disposez de Docker. Sachez que Glances est aussi compatible avec LXC. Ci-dessous un exemple de fichier Docker Compose (docker-compose.yml) pour déployer Glances avec Docker : services: glances: container_name: glances image: nicolargo/glances:latest ports: - 61208:61208 environment: - TZ=Europe/Paris - GLANCES_OPT=-w pid: host restart: unless-stopped volumes: - /var/run/docker.sock:/var/run/docker.sock:ro L'application Glances sera accessible via un navigateur web sur l'adresse de l'hôte Docker, via le port 61208 : http://<IP Docker>:61208. Cela est possible grâce à l'activation de l'interface web de Glances via GLANCES_OPT=-w. Pour aller plus loin, voici un autre exemple où Glances est publié via Traefik et l'accès à son interface est protégé par une page d'authentification Tinyauth. services: glances: container_name: glances image: nicolargo/glances:latest environment: - TZ=Europe/Paris - GLANCES_OPT=-w pid: host restart: unless-stopped volumes: - /var/run/docker.sock:/var/run/docker.sock:ro networks: - frontend labels: - traefik.enable=true - traefik.http.routers.glances-https.rule=Host(`glances.domaine.fr`) - traefik.http.routers.glances-https.entrypoints=websecure - traefik.http.routers.glances-https.tls=true - traefik.http.routers.glances-https.tls.certresolver=ovhcloud - traefik.http.routers.glances-https.middlewares=crowdsec@file,tinyauth - traefik.http.services.glances-https.loadbalancer.server.port=61208 - tinyauth.apps.glances.config.domain=glances.domaine.fr - tinyauth.apps.glances.users.allow=adm_fb networks: frontend: external: true Remarque : si vous envisagez de personnaliser la configuration de Glances, vous devez ajouter un volume pour le fichier glances.conf. Par exemple : - "./glances.conf:/glances/conf/glances.conf". D'autres exemples sont disponibles sur GitHub du projet Glances : Docker Compose Glances. Pour lancer l'outil, ouvrez simplement votre terminal et tapez cette commande : glances L'interface de Glances apparaît immédiatement à l'écran. Elle se divise en plusieurs zones dynamiques où les informations sont actualisées en permanence (avec un délai d'actualisation de 2 secondes par défaut). Sur les versions récentes, il y a aussi un mode plus synthétique pour obtenir un résumé de votre machine. Ce mode s'exécute de cette façon : glances --fetch C'est probablement l'une des fonctionnalités les plus appréciées. Glances peut lancer un petit serveur web intégré, vous permettant de consulter vos métriques depuis n'importe quel navigateur, y compris sur mobile. Pour lancer ce mode, rajoutez simplement cette option : glances -w Glances Web User Interface started on http://0.0.0.0:61208/ Glances RESTful API Server started on http://0.0.0.0:61208/api/4 Announce the Glances server on the LAN (using 0.0.0.0 IP address) INFO: Started server process [5087] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:61208 (Press CTRL+C to quit) Le terminal affiche un message précisant que Glances écoute sur http://0.0.0.0:61208. Vous pouvez donc y accéder en local ou à distance en précisant l'adresse IP de votre machine. Note : par défaut, le mode web est ouvert à tous. Il est conseillé de définir un mot de passe avec l'option --password. Ce qui donne : glances -w --password. Il conviendra alors de définir un mot de passe associé au compte utilisateur glances (pour changer, utilisez --username). Ce mode permet de centraliser la surveillance. Vous lancez Glances en mode "serveur" sur la machine à surveiller, et vous vous y connectez depuis votre poste de travail (le client). Sur le serveur (la machine à surveiller) : glances -s Sur la machine de supervision (client) : glances -c <IP_SERVEUR_GLANCES> L'interface de Glances, qu'elle s'affiche dans le Terminal ou via la page Web, affiche un ensemble de métriques sur votre système. Ces informations sont réparties dans un ensemble de zones. La zone principale se situe en bas à droite et donne un aperçu sur tous les processus en cours d'exécution sur la machine. Il y a plusieurs métriques, dont : usage du CPU, usage de la RAM, PID, temps d'exécution, le compte associé, ou encore la commande complète ou le service associé au processus. Juste au-dessus, vous avez la liste des conteneurs en cours d'exécution sur la machine locale. Avec là encore, des métriques spécifiques : le nom du conteneur, le statut, l'uptime, la consommation en RAM et CPU, et les ports exposés. Glances supporte Docker et Podman. En complément, il y a d'autres zones permettant d'avoir des informations sur l'état du stockage, l'état du réseau, la charge globale du système sur 1, 5 et 15 minutes, et la charge de la RAM et du CPU à l'échelle du système. Glances utilise un système de seuils colorés pour attirer votre attention, ce qui facilite la lecture rapide : Vert (OK) : tout est normal. Bleu (Careful) : une vigilance est requise (exemple : CPU > 50%). Violet (Warning) : la charge est élevée (exemple : CPU > 70%). Rouge (Critical) : le système est en situation critique (exemple : CPU > 90%). Ces seuils sont entièrement configurables via le fichier de configuration glances.conf. Bien qu'il y ait quelques zones cliquables, la navigation sur l'interface de Glances s'effectue majoritairement au clavier. Au-delà de la navigation avec les flèches directionnelles, voici quelques raccourcis pratiques : c : trier les processus par utilisation CPU. m : trier les processus par utilisation mémoire. p : trier les processus par nom. q : quitter l’application. L'aide, accessible via la touche h du clavier, permet d'obtenir la liste complète des raccourcis clavier : Glances dispose d'un fichier de configuration en mode texte que vous pouvez utiliser pour affiner le comportement de la solution. Ce n'est pas obligatoire d'éditer la configuration, car Glances est prêt à l'emploi dès sa sortie de boite. Sur Linux (Debian/Ubuntu), le fichier de configuration est le suivant : /etc/glances/glances.conf. Si vous utilisez Glances sur Windows, ce sera bien entendu différent : %APPDATA%\glances\glances.conf. Vous pouvez notamment utiliser ce fichier de configuration pour personnaliser les seuils d'alerte de Glances et la fréquence à laquelle les données doivent être rafraichies. Le fichier de configuration commence par la section [global] : [global] # Temps d'actualisation global, personnalisable au niveau de chaque module # Par exemple, un temps d'actualisation plus rapide pour le CPU. refresh=2 # Vérifier la présence de mises à jour check_update=true # Taille de l'historique, en nombre de valeurs # 1200 valeurs = 1 heure avec le refresh à 2 secondes history_size=1200 Il y a ensuite des sections par module, par exemple [system] (première ligne de l'interface Glances), [cpu] pour les informations globales sur le processeur ou encore [mem] pour la RAM. Vous avez à chaque fois des paramètres communs, comme disable=False si un module est activé, et des paramètres pour la personnalisation des seuils (careful, warning, critical). Par ailleurs, vous pouvez configurer l'exporter Prometheus pour ensuite afficher les informations avec Grafana. Cette configuration s'effectue dans le même fichier de configuration, via la section [prometheus]. Voici la configuration suggérée (et par défaut) : [prometheus] host=localhost port=9091 prefix=glances labels=src:glance Pour activer l'export, vous devez lancer Glances de cette façon : glances --export prometheus Pour en savoir plus et obtenir des précisions sur les paramètres, consultez cette page : Documentation Glances - Configuration. Glances se positionne comme un outil de monitoring "tout-en-un" très pertinent pour l'administration système quotidienne. Sa capacité à s'exécuter en mode web ou client/serveur lui confère une polyvalence que les outils standards n'ont pas toujours. Bien qu'il ne remplace pas une solution de supervision complète comme Centreon ou Zabbix pour l'historisation à long terme, il est un allié de choix pour l'analyse en temps réel. Afficher l’article complet -
www.cachem.fr Publié le 24 octobre 2025 cachem.fr Environ 2 minutes de lecture Après une année de développement et de tests intensifs, Jellyfin 10.11.0 marque l’une des évolutions les plus importantes du projet open source. Cette nouvelle version met l’accent sur la performance, la fiabilité et la préparation du futur, avec une refonte du système de gestion des métadonnées, de nouveaux outils d’administration et plusieurs améliorations côté utilisateur. Regardons de plus près cette nouvelle version… Jellyfin 10.11.0 : le changement, c’est maintenant Visuellement, Jellyfin 10.11.0 n’apporte que peu de modifications. Les véritables avancées se situent à l’intérieur du moteur : la base de données de la bibliothèque a été entièrement migrée vers EF Core. Concrètement, Jellyfin abandonne les requêtes SQLite dispersées au profit d’une gestion centralisée des données. Résultat : des requêtes plus rapides, des migrations plus sûres, et une base bien plus facile à faire évoluer. Cette refonte ouvre également la voie à la prise en charge future d’autres moteurs de base de données, comme PostgreSQL, pour plus de flexibilité et de robustesse. Maintenance simplifiée La migration des bibliothèques s’accompagne d’un processus de déduplication et de nettoyage des données (suppression d’entrées orphelines ou doublons). Selon la taille et l’ancienneté de la base, cette étape peut durer de quelques minutes à plusieurs heures. Avant toute mise à jour, il est impératif de : sauvegarder manuellement les dossiers de données et de configuration, être déjà sur la version 10.10.7, et ne jamais interrompre la migration en cours. Autre nouveauté appréciable : la fonction de sauvegarde et restauration intégrée. Elle permet de créer des instantanés (snapshots) de la base de métadonnées et de les restaurer facilement, un vrai plus pour la maintenance et la sécurité des données. Performances et consommation mémoire Le moteur de base de données tire désormais parti d’un cache en mémoire plus agressif, ce qui réduit les accès disque et améliore nettement la réactivité, notamment sur les grandes bibliothèques. En contrepartie, Jellyfin utilise davantage de RAM, mais cette mémoire est libérée automatiquement si d’autres processus en ont besoin. De nouveaux modes de verrouillage (locking) viennent aussi améliorer la stabilité dans les environnements sollicités. Compatibilité et évolutions techniques Jellyfin abandonne définitivement le support des systèmes ARM 32 bits (armhf). Pour continuer à bénéficier des mises à jour, il faut désormais utiliser un système d’exploitation ARM64. Autre changement annoncé : la suppression prochaine du support TLS/SSL interne (prévue pour la version 10.12.0). Les développeurs recommandent désormais d’utiliser un reverse proxy (comme Nginx ou Caddy) pour la gestion des certificats, plus fiable et plus simple à maintenir. Nouvelles fonctionnalités et améliorations clés Parmi les nouveautés les plus notables de Jellyfin 10.11.0 : Recherche plus rapide et gestion enrichie des favoris (Live TV, clips, albums photo, saisons, etc.) ; Support HEVC dans Firefox 134+ et option pour désactiver le style natif des sous-titres ; Affichage en collections des séries et ajout d’un splash screen personnalisable sur la page de connexion ; Tableau de bord enrichi, avec statistiques médias et suivi de l’espace disque ; Support AV1 via VideoToolbox et passage à FFmpeg 7.1, pour de meilleures performances en décodage et transcodage ; Amélioration du rendu HDR et Dolby Vision sur certains matériels compatibles ; Nouvelle API de sauvegarde (BackupApi) et migration complète des plugins vers EF Core. Cette version corrige également plusieurs failles de sécurité, y compris des correctifs issus de projets externes. En synthèse Jellyfin 10.11.0 pose des fondations solides pour l’avenir du projet. Plus rapide, plus stable et mieux structurée, cette version facilite la maintenance tout en préparant de futures innovations. Une mise à jour vivement conseillée, à condition de la planifier avec soin…. pensez aux sauvegardes. source Afficher l’article complet
-
Linux TrueNAS CE : le gestionnaire de stockage basique et simple - UpAndClear
Ldfa a posté un sujet dans Mon Wallabag
upandclear.org upandclear.org Environ 5 minutes de lecture J’ai migré mon LincStation N1 d’UNRAiD à TrueNAS CE (ex TrueNAS Scale, ex FreeNAS), que je redécouvre avec grand plaisir. EDIT : on peut passer l’interface en français dans les options, tout comme on peut choisir son shell (zsh de base, je suis repassé en Bash) EDIT2 : oui, mon titre est réducteur. Très longtemps utilisateur de ProxMox, depuis l’avènement de Docker je me servais de moins en moins les VM/CT. Après l’avoir utilisé avec Docker (directement sur l’hôte), j’ai ensuite bifurqué sur du 100% Linux sans interface chez moi avec Debian, Ubuntu et ArchLinux. Ce dernier n’étant pas le plus stable pour un serveur, vu le principe de rolling release, il faut être à l’aise avec Arch dans ce contexte. Trouvant OpenMediaVault inadapté à mes besoins, Xpenology (comme un hackintosh mais pour DSM de Synology) encore moins pour un serveur de prod, j’avais fait un passage par TrueNAS Scale à l’époque mais le trouvais là encore trop peu pratique dans mon cas (manquant de simplicité). En me rapprochant de SuperBoki, je m’étais acheté une licence Pro à vie d’UNRAiD puis un LincStation N1 à l’occasion de sa promotion sur le site d’UNRAiD. Petit serveur, aussi bien physiquement qu’en terme de ressources, ce petit NAS basse consommation répond toujours très bien à mes besoins (hors post sur Usenet, le pauvre CPU ayant morflé quelques fois…). Au fil du temps, j’allais surtout sur UNRAiD pour parcourir le magasin d’applications et faire quelques découvertes, UNRAiD étant très populaire chez les hoarders et dans l’univers de l’auto-hébergement lié au P2P and co. Mais je n’y allais que pour ça. Au final, UNRAiD ne me servait qu’à avoir une gestion simplifiée et très user-friendly du stockage. Je gérais, quasi depuis le début, mes Dockers comme j’aime, donc pas via UNRAiD : en console, via Dockge voire Portainer ou plus récemment Arcane. Des outils qui, à mon sens, ne dépendant pas de l’OS, permettent une plus grande liberté d’actions, manipulations et migrations entre machines (j’en ai actuellement 3 au garage). Et en plus quand un truc tourne rond, je suis de ceux qui ne sont pas contents, je pense que c’est le lot des bidouilleurs. J’ai récemment remisé dans un tiroir ma clé USB UNRAiD et décidé passer ce petit NAS sous TrueNAS CE, l’évolution de Scale (donc la version gratuite). Mon but cette fois-ci était précis : trouver un gestionnaire de stockage simple et efficace, qui me laisse beaucoup de liberté de gestion tout en me permettant de gérer mon stockage de manière très intuitive (autrement qu’en console via mdadm). Je ne vais pas présenter l’OS vu que je ne m’y suis pas vraiment attardé autrement que pour la gestion des disques et partages. Il permet de créer VM, CT et mettre en place des Dockers. Il propose, comme UNRAiD mais bien moins fourni, un magasin d’applications (environ 300 pour l’instant, rien de comparable à UNRAiD donc et logiquement orientées pro/services plus que P2P etc). J’utilise ZFS pour créer mes pools (des VDEVs) de stockage. Docker, RAID1 de 2 NVMe de 250Go. Ne remplace pas une sauvegarde régulière mais me permet la perte d’un disque pour reconstruire le RAID sans perdre les données. Fichiers, en stripped (RAID0) de 2 SSD de 2To. Si un disque meurt, tout le pool est irrécupérable. Dédié à BitTorrent etc, que des données que je peux perdre. Usenet, composé d’un seul disque NVMe d’1To. Parce que je ne savais vraiment pas quoi en faire… Il pourrait me servir à faire un peu de DL/Post pour Usenet. Il me reste encore un disque d’inutilisé. Si je décide de remettre Plex/Jellyfin, il pourrait servir de cache. J’ai pas utilisé de chiffrement, il n’y a aucun service confidentiel dessus et en plus c’est stocké chez moi. Je fais des backups de mes Dockers à l’ancienne via un script Bash pour l’instant (oui je sais, on arrive en 2026). Il va falloir que je me penche sur les options intégrées à TruenAS ! J’aime la gestion simplifiée des services Idem pour les partages. On voit d’ailleurs que j’ai fait en sorte de pouvoir monter Fichiers sur mon Windows de jeu, vu que j’ai le temps de jouer en ce moment (…) pour récupérer mes jeux téléchargés. Là encore, la gestion des utilisateurs est étonnante de simplicité et pourtant très complète Je redécouvre cet OS avec grand plaisir, notamment avec le recul que j’ai pris à écrire cet article. Je le trouve bluffant de simplicité sans pour autant faire de concession sur la sécurité ou les options. Même si j’ai conscience de ne pas l’exploiter, j’ai enfin trouvé un OS qui répond à mes besoins du moment, se configure en 8 minutes et me laisse libre de l’utiliser comme bon me semble. On peut gérer cron et systemd via ses options également. Ravi d’avoir retenté l’expérience TrueNAS 🙂 Afficher l’article complet -
Vous avez apprécié mon calendrier de l'Avent spécial Open Source ? Ou pire encore, vous l'avez totalement manqué ? Voici un récapitulatif complet des outils présentés du 1er au 24 décembre 2025 dans le cadre du calendrier de l'Avent publié sur mon compte LinkedIn. Pour clôturer cette année 2025, je vous ai proposé un voyage quotidien au cœur de l'Open Source en reprenant le principe d'un calendrier de l'Avent. Le principe était simple : présenter chaque jour un nouvel outil open source. Il y a des milliers de projets open source, alors comment choisir ? Surtout pas au hasard. J'ai sélectionné des projets que je connaissais déjà ou qui me semblaient avoir un potentiel intéressant. Voici désormais la synthèse complète des 24 outils présentés jour après jour. Nuclei est un scanner de vulnérabilités rapide et personnalisable basé sur des modèles (templates) simples à écrire. Il permet aux équipes de sécurité et aux professionnels de l'IT d'une manière générale, d'automatiser la détection de failles sur des applications web et des infrastructures. Grâce à sa communauté active, de nouveaux modèles sont constamment ajoutés et mis à jour pour détecter les dernières CVE. On peut citer notamment les points clés suivants : Détection de CVE connues Repérage de fichiers sensibles et logins par défaut Identification de pages d'administration Identification des signatures applicatives Création de templates personnalisables en YAML Voici quelques ressources utiles : Pangolin se positionne comme une alternative complète et auto-hébergée aux tunnels Cloudflare, utilisant la puissance de WireGuard et que vous pouvez déployer sur votre machine. Cette solution de plus en plus populaire permet d'exposer vos applications locales sur Internet sans que vous ayez à ouvrir de ports sur votre routeur, ni à vous prendre la tête avec des problèmes de NAT. L'outil intègre un tableau de bord intuitif pour gérer vos accès et sécuriser vos flux. Quelques points clés : Exposition d'applications via des tunnels WireGuard Gestion des règles d'accès contextuelles (IP, Géo, etc.) : application du principe Zero-trust Tableau de bord de configuration complet Routage du trafic vers n'importe quel réseau privé Applications pour Mac, Windows et Linux Voici quelques ressources utiles : GitHub : fosrl/pangolin Site officiel : pangolin.net Source : GitHub - Pangolin FossFLOW est un outil spécialisé dans la création de diagrammes d'infrastructure réseau avec une approche bien à lui : une vue isométrique. Je trouve qu'il est idéal pour schématiser des architectures, des flux applicatifs ou des topologies réseau de manière claire. L'application fonctionne directement dans le navigateur et facilite la documentation technique visuelle : vous pouvez l'auto-héberger sur votre serveur. Voici quelques ressources utiles : GitHub : stan-smith/FossFLOW Démo en ligne : fossflow Source : GitHub - FossFLOW BunkerWeb est un pare-feu applicatif web (WAF) open source de nouvelle génération, basé sur le célèbre serveur Nginx. Développé par une équipe de Français, il est conçu pour s'intégrer dans des environnements modernes comme Docker et Kubernetes, tout en prenant en charge les hôtes classiques. Son interface d'administration full-web rend plus agréable la gestion de la sécurité de vos sites et applications web. Administration 100% web Protection contre les bots et les IP malveillantes (intégration de certaines listes) Intégration native de ModSecurity (moteur pour le WAF) Compatible Linux, Docker et orchestrateurs Quelques ressources utiles : Référence historique de l'open source, Samba continue d'évoluer pour offrir une alternative crédible et gratuite à Microsoft Active Directory. Il permet de monter un contrôleur de domaine complet, gérant l'authentification et les droits des utilisateurs dans un réseau Windows/Linux. C'est la solution idéale pour avoir les avantages d'un Active Directory sans s'appuyer sur Windows Server, et ainsi s'affranchir des coûts de licences CAL Microsoft. En résumé, on peut citer la prise en charge des fonctions suivantes : Contrôleur de domaine (DC) Gestion des GPO (Group Policy Objects) Authentification Kerberos Partage de fichiers et compatibilité RSAT Quelques ressources utiles : GitLab : samba-team/samba Site officiel : samba.org Jellyfin est le système multimédia qui vous permet de reprendre le contrôle sur vos données audio et vidéo. Il centralise vos films, séries, musiques et photos pour les diffuser sur n'importe quel appareil via une interface moderne. Contrairement à Plex, il est totalement gratuit et sans fonctionnalités payantes. Une solution stable et agréable à utiliser au quotidien, surtout pendant les longues soirées d'hiver. Quelques points clés : Centralisation de tous vos médias Transcodage vidéo matériel (Hardware Transcoding) Gestion automatique des métadonnées (recherche dans plusieurs bases connues) Prise en charge de nombreux appareils et systèmes d'exploitation, autant desktop que mobile et TV Fonction SyncPlay pour regarder à plusieurs Voici des ressources utiles : Source : Jellyfin.org Immich est une solution de sauvegarde de photos et vidéos auto-hébergée conçue pour remplacer Google Photos. Avec son interface web moderne, elle offre une expérience utilisateur agréable avec de nombreuses fonctionnalités pour organiser vos photos et vidéos. L'outil intègre même des fonctionnalités avancées d'intelligence artificielle locale pour la reconnaissance faciale et la recherche : j'insiste sur le mot "locale", car immich est une solution focus sur la privacy. Quelques fonctionnalités clés : Gestion et partage d'albums Applications mobiles pour la sauvegarde automatique de vos clichés en arrière-plan. Vue cartographique et recherche intelligente Gestion multi-utilisateurs Corbeille et archivage de données Voici les liens vers des ressources utiles : Tabby est un terminal ultra-personnalisable : il va au-delà du simple terminal en intégrant un gestionnaire de connexions complet et le support de multiples protocoles (SSH, Telnet, Serial). Son interface moderne et ses plugins en font un outil intéressant dans la catégorie "productivité" pour aller plus loin que Windows Terminal sur Windows. Terminal moderne et personnalisable Gestionnaire de connexions et coffre-fort intégré Support de nombreux types de connexion : SSH, Telnet, Serial, etc. Support de PowerShell, Bash, WSL, etc. Cross-platform (Windows, Mac, Linux) Quelques liens utiles : GitHub : Eugeny/tabby Site officiel : tabby.sh Source : Tabby.sh SearXNG est un métamoteur de recherche gratuit qui agrège les résultats de plus de 70 services de recherche tout en protégeant votre vie privée. Il ne traque pas les utilisateurs et ne crée pas de profilage, garantissant des résultats neutres. En l'hébergeant vous-même, vous reprenez le contrôle total sur vos requêtes web sans pour autant vous passer de Google. Agrégateur de résultats (Google, Bing, etc.) Respect total de la vie privée Résultats neutres sans bulles de filtres Sources et interface personnalisables (onglets de recherche personnalisés selon un contexte) Quelques liens utiles : GitHub : searxng/searxng Site officiel : docs.searxng.org Quand on parle de no-code, on pense à n8n : c'est normal, c'est un outil très à la mode et qui est vraiment top ! Mais, il n'est pas open source (fair-code), donc il n'a pas été retenu pour ce calendrier de l'Avent. Une autre alternative que j'apprécie a été présentée : Activepieces, une plateforme d'automatisation open source conçue pour être une alternative à différents outils comme Zapier (et n8n). Elle permet de connecter vos applications entre elles (noeuds) et de créer des flux de travail complexes via une interface visuelle. Avec le support de TypeScript et des agents IA, c'est un outil flexible pour automatiser vos tâches. Automatisation de workflows via éditeur visuel Création d'agents IA personnalisés et prise en charge de serveurs MCP Plus de 500 connecteurs disponibles Pièces (modules) écrites en TypeScript avec une grosse participation de la communauté Voici quelques liens utiles : GitHub : activepieces/activepieces Site officiel : activepieces.com DocuSeal offre une plateforme pour signer, gérer et stocker vos documents numériques sans utiliser des outils comme DocuSign ou Adobe Sign. Elle permet de créer des formulaires PDF remplissables et de les faire signer légalement par des tiers, en respectant l'ordre de signature. La version auto-hébergée lève les limites de volume, idéale pour les entreprises soucieuses de la souveraineté de leurs données. Signature numérique et audit légal Création de formulaires PDF Signatures illimitées en version self-hosted Intégration d'un certificat personnel pour avoir une signature valide et vérifiable API et Webhooks pour l'intégration Quelques ressources utiles : Uptime Kuma est un outil de surveillance self-hosted facile à déployer, doté d'une interface à la fois soignée et épurée. Il surveille la disponibilité de vos services en effectuant une vérification simple (HTTP, HTTPS, TCP, DNS, etc.) et vous alerte instantanément en cas de panne sur le canal de votre choix (des dizaines de services sont pris en charge). Il permet également de créer des pages de statut publiques pour vos utilisateurs, comme le font les hébergeurs. Monitoring HTTP(s), TCP, Ping, DNS, Docker, etc. Tableau de bord moderne et réactif Page de statut publique (Status Page) Notifications via E-mail, Telegram, Slack, etc. Quelques ressources utiles : LanguageTool est un assistant d'écriture intelligent qui va bien au-delà du simple correcteur orthographique classique. Il analyse la grammaire, le style et le ton de vos textes dans plusieurs langues pour améliorer la qualité de vos écrits. En version auto-hébergée, il garantit que vos textes ne quittent jamais votre serveur et cela permet d'avoir une instance centralisée pour plusieurs utilisateurs. Je l'utilise au quotidien depuis plusieurs années, notamment pour la rédaction des articles, et je ne peux plus m'en passer. Il y a des extensions pour les principaux navigateurs et certaines applications comme Word et LibreOffice (sans oublier le module Google Docs). Quelques ressources utiles : Stirling-PDF est une application web regroupant des dizaines d'outils pour manipuler des fichiers PDF. En gros, vous avez tout ce qu'il vous faut pour fusionner, découper, convertir, signer ou encore effectuer de l'OCR sur vos documents, le tout via une interface web unique. C'est un outil pertinent pour remplacer les services PDF en ligne où vous ne savez pas ce que deviennent vos données : là, vous pouvez l'auto-héberger. Plus de 50 outils pour manipuler les PDF Fonctionne directement dans le navigateur OCR (Reconnaissance optique de caractères) Signature numérique et conversion de formats Une API pour faciliter les interactions avec des outils tiers Interface configurable en 40 langues différentes Dans le même esprit, il y a un autre projet qui mérite une attention particulière et qui monte bien ces derniers temps : BentoPDF. Quelques liens utiles : GitHub : Stirling-Tools/Stirling-PDF Site officiel : stirlingpdf.com Stirling-PDF (ancienne version) XCP-ng est une plateforme de virtualisation, née comme alternative communautaire à Citrix Hypervisor. C'est un hyperviseur de type bare-metal qui offre toutes les fonctionnalités attendues en production, et qui se présente donc comme une alternative à VMware ESXi, Proxmox VE ou encore Hyper-V. Il est soutenu par une entreprise française (Vates) et une communauté grandissante : une solution qui mérite un peu plus de lumière ! Live Migration de machines virtuelles (migration à chaud) Haute disponibilité avec le clustering Aucune restriction sur le CPU ou la RAM Support Pro pour les entreprises Quelques liens utiles : GitHub : xcp-ng/xcp-ng Site officiel : xcp-ng.org Source : GitHub - XCP-ng BorgBackup (ou Borg pour les intimes) est une solution de sauvegarde en ligne de commande qui dispose d'un jeu de commandes très complet. BorgBackup supporte la déduplication des données (top pour optimiser l'utilisation du stockage) et permet de réaliser des sauvegardes quotidiennes, tout en chiffrant les données côté client. C'est un outil très intéressant pour la sauvegarde de serveurs Linux. Déduplication efficace (gain de place) Sauvegardes incrémentales Chiffrement authentifié et compression Support natif du SSH Grâce au projet Borg-UI, vous pouvez lui ajouter une interface web pour faciliter la configuration ! Source : GitHub - Borg-UI Quelques liens utiles : GitHub : borgbackup/borg Site officiel : borgbackup.org Papra est une plateforme d'archivage de documents minimaliste pour organiser vos archives personnelles ou professionnelles. Beaucoup plus légère que Paperless-Ngx, la solution Papra facilite le tri, le taggage et la recherche de documents numérisés ou importés. L'outil propose des fonctionnalités pratiques comme l'importation automatique depuis une boîte mail. Papra est développé par un Français, qui est aussi à l'origine de IT-Tools. Archivage et organisation par tags Recherche efficace dans les documents API, Webhooks et CLI disponibles Importation automatique par e-mail Quelques liens utiles : GitHub : papra-hq/papra Site officiel : papra.app Source : GitHub - Papra Sync-in est une solution de cloud privé qui met l'accent sur la collaboration et le partage sécurisé de fichiers. Chaque utilisateur dispose de son espace personnel (comme un Drive) pour stocker ses fichiers et y accéder depuis n'importe où. En tant qu'alternative à nextCloud, Sync-in permet aussi de créer des espaces de travail dédiés où plusieurs utilisateurs peuvent éditer et synchroniser des documents en ligne (via l'intégration d'OnlyOffice). Espaces collaboratifs (spaces) Édition en ligne multi-utilisateurs Applications officielles et prise en charge du WebDAV Recherche full-texte Visionneuse en ligne Partage via liens publics sécurisés Quelques liens utiles : Source : Sync-in.com CrowdSec est un système de détection d'intrusions (IDS) collaboratif qui protège vos serveurs en temps réel. Le principe est simple : lorsqu'une adresse IP attaque votre serveur, elle est bloquée sur votre serveur. Ce n'est pas tout, elle est aussi signalée à la communauté, permettant à tous les utilisateurs de se prémunir contre cette menace (s'il y a plusieurs signaux négatifs à son sujet). Pour aller plus loin, grâce à son modèle AppSec, il peut agir comme un WAF capable de sécuriser les services exposés. Détection et blocage d'IP malveillantes Logique communautaire (l'attaque de l'un protège les autres) que n'a pas Fail2ban Module AppSec pour le transformer en véritable WAF Console de Threat Intelligence Synchronisation des adresses IP bloquées entre plusieurs instances CrowdSec Quelques liens utiles : GitHub : crowdsecurity/crowdsec Site officiel : crowdsec.net IT-Connect : les tutoriels CrowdSec Audiobookshelf est un serveur multimédia spécialisé conçu pour gérer et diffuser vos collections de livres audio et de podcasts. Il propose une interface web dans le même style que Spotify et des applications mobiles qui synchronisent votre progression de lecture partout. C'est l'outil adéquat pour les amateurs de contenu audio ! On peut citer quelques fonctions clés : Applications pour Android & iOS Gestion de plusieurs utilisateurs Synchronisation de la progression de lecture Gestion avancée des métadonnées Interface utilisateur intuitive Voici quelques liens utiles : GitHub : advplyr/audiobookshelf Site officiel : audiobookshelf.org Source : GitHub - Audiobookshelf Netdata est un outil de monitoring en temps réel conçu pour offrir une visibilité immédiate et granulaire sur les performances de vos systèmes. On parle alors d'observabilité. Il adopte une approche Zero Config pour faciliter la découverte des services et collecte de nombreuses métriques, présentées dans des graphiques interactifs (et une superbe interface). Il vous permet de mieux comprendre vos systèmes. Monitoring en temps réel Tableau de bord interactif et moderne Plus de 800 intégrations disponibles Approche "Zero Config" avec alertes pré-configurées Quelques liens utiles : GitHub : netdata/netdata Site officiel : netdata.cloud Source : Netdata ChangeDetection.io est un outil de veille qui surveille les changements sur n'importe quelle page web. Que ce soit pour suivre l'évolution d'un prix, la disponibilité d'un produit en stock, la publication d'une nouvelle version (logiciel, pilote, etc.) ou la modification d'un texte sur une page, il vous notifie dès qu'une différence est détectée. Il supporte des scénarios complexes grâce à son intégration avec Playwright où il peut simuler l'exécution d'un navigateur Chrome. Quelques liens utiles : PatchMon est une solution dédiée à la surveillance de l'état des mises à jour de vos serveurs Linux. Il permet de visualiser en un coup d'œil quels serveurs nécessitent des correctifs, en mettant notamment en évidence les correctifs de sécurité. L'outil utilise des agents légers qui remontent l'inventaire des paquets vers un tableau de bord central (donc pas de port à ouvrir sur vos serveurs, puisqu'on pousse l'information vers le serveur PatchMon). Voici quelques liens utiles : GitHub : PatchMon/PatchMon Site officiel : patchmon.net Source : GitHub - PatchMon RustDesk est une solution de prise en main à distance open source codée en Rust. Vous l'aurez compris, c'est une alternative à TeamViewer ou AnyDesk. Sa particularité, c'est qu'il vous permet d'héberger votre propre serveur relais (Rendezvous Server), pour une meilleure confidentialité et surtout sans dépendre d'un tiers. Côté sécurité, les connexions sont chiffrées de bout en bout, garantissant la sécurité des sessions. On peut citer : Prise en main à distance (Windows/Mac/Linux) Applications mobiles et version portable Serveur auto-hébergeable pour une souveraineté totale Connexion P2P avec chiffrement de bout en bout Je l'avais présenté sur IT-Connect il y a quelques années, mais il faudrait que j'actualise mon contenu. Voici quelques liens utiles : GitHub : rustdesk/rustdesk Site officiel : rustdesk.com Source : RustDesk.com J'espère que cette sélection vous donnera des idées pour vos projets en 2026, que ce soit dans un contexte professionnel ou pour votre Home Lab. N'hésitez pas à tester ces outils ! J'envisage d'en présenter certains avec des articles dédiés et probablement des vidéos. Pensez à me dire en commentaire ceux que vous aimeriez voir présentés par mes soins sur IT-Connect ! Passez une belle fin d'année. Source : https://www.it-connect.fr/calendrier-de-lavent-2025-24-outils-open-source-a-decouvrir/
-
durée de lecture : 2 min J’sais pas si vous vous souvenez, mais le RSS c’était LA révolution du web dans les années 2000 et moi, je suis toujours un fan absolu de ce format ! Alors pendant que tout le monde se laisse gaver le cervelet par les algos de Twitter, Facebook et compagnie, moi je continue de suivre mes sources d’info préférées via RSS. Et je suis également l’un des derniers médias tech / blogs tech grand public à proposer un flux RSS complet avec tout dedans et pas un truc tronqué avec juste le titre et deux lignes pour vous forcer à cliquer. Ceux qui me suivent encore via le flux RSS, vous êtes mes gars et filles sûr(e)s ! Mon problème vous l’aurez compris, c’est que la plupart des sites web ont abandonné leur flux RSS sans oublier que Twitter, Instagram, YouTube, TikTok… aucun de ces services ne propose de flux natif. Heureusement, pour les furieux comme vous et moi, y’a RSSHub , un projet open source qui permet de générer des flux RSS pour à peu près n’importe quel site web. RSSHub peut s’auto-héberger et permet de scraper les sites qui n’offrent pas de RSS pour ensuite générer des flux à la volée. Le projet supporte des centaines de sources différentes telles que YouTube, Twitter, Instagram, Telegram, Spotify, TikTok, Bilibili (vous connaissiez ?), et des tonnes d’autres plateformes chinoises et occidentales. En gros, si un site existe, y’a probablement une route RSSHub pour lui. Pour l’utiliser, vous avez donc deux options. Soit vous utilisez une des instances publiques listées ici , soit vous déployez votre propre instance via Docker . La deuxième option est recommandée si vous voulez éviter les limitations de débit des instances publiques et garder vos abonnements privés, évidemment. Et pour faciliter la découverte des flux disponibles, le même développeur (DIYgod) a créé RSSHub-Radar , une extension navigateur disponible pour Chrome, Firefox, Edge et Safari. Comme ça, quand vous visitez un site, elle vous montre automatiquement tous les flux RSS disponibles, qu’ils soient natifs ou générés par RSSHub. Super pratique donc pour ne plus jamais rater un flux caché. D’ailleurs, en parlant de RSS, c’est impossible pour moi de ne pas mentionner Aaron Swartz , ce génie qui a contribué à créer le format RSS 1.0 alors qu’il n’avait que 14 ans en 2000. Ce mec a aussi co-fondé Reddit, co-créé Markdown (le format que vous utilisez sur GitHub, Discord et partout ailleurs), travaillé sur Creative Commons, et développé SecureDrop pour protéger les lanceurs d’alerte. Sa vision d’un web ouvert et accessible à tous reste plus pertinente que jamais. Malheureusement, il nous a quittés en 2013 à seulement 26 ans, harcelé par la justice américaine pour avoir voulu libérer des articles scientifiques. Une perte immense pour le web libre. Bref, RSSHub c’est le truc à installer si vous voulez arrêter de vous faire gaver par les algos. Pour moi, le RSS c’est encore aujourd’hui la meilleure façon de rester maître de sa veille et je trouve ça vraiment dommage que les gens aient “oublié” à quel point c’était génial… Cet article peut contenir des images générées à l'aide de l'IA - J'apporte le plus grand soin à chaque article, toutefois, si vous repérez une boulette, faites-moi signe ! Afficher l’article complet
-
Je suis enfin arrivé à jouer à mes jeux favoris sous Linux, et sans trop de difficulté finalement... J'ai installé la distribution Linux Pop!_OS qui est prête pour jouer sous Linux, en suivant ce tuto : Après l'installation et le redémarrage, ainsi que les quelques outils supplémentaires indiqués dans la vidéo précédente, voici la copie d'écran réalisée en jouant à Trackmania Stadium. Le jeu est très fluide, comme sous Windows, c'est parfait.
-
Proxmox Quelles sont les nouveautés de Proxmox VE 9.1 ? - IT Connect
Ldfa a posté un sujet dans Mon Wallabag
durée de lecture : 2 min L'hyperviseur open source Proxmox VE évolue avec la sortie d'une nouvelle version : Proxmox VE 9.1. Quelles sont les nouveautés introduites par cette mouture disponible depuis le 19 novembre 2025 ? Voici un récapitulatif. LXC depuis des images OCI, snapshots vTPM et virtualisation imbriquée La nouveauté la plus marquante est sans doute l’intégration de la prise en charge des images OCI (Open Container Initiative) pour la création de conteneurs LXC. C'est réellement une nouveauté importante pour Proxmox VE. Il est désormais possible d'importer ou de télécharger des images standardisées depuis des registres publics afin d’en faire des modèles LXC. Ce standard est notamment utilisé par le Docker Hub. Pour autant, cela ne signifie pas que Proxmox VE intègre Docker, car il n'utilise pas le moteur Docker. Il continue d'utiliser LXC avec la capacité d'utiliser des images prêtes à l'emploi. "Selon l'image, ces conteneurs sont provisionnés en tant que conteneurs système complets ou conteneurs d'application allégés. Les conteneurs d'application constituent une approche distincte et optimisée qui garantit un encombrement minimal et une meilleure utilisation des ressources pour les microservices.", précise Proxmox. Côté machines virtuelles, Proxmox VE 9.1 introduit la prise en charge du stockage de la puce vTPM dans le format qcow2. Cette amélioration permet de créer des snapshots complets de VM équipées d’un vTPM, y compris sur des stockages tels que NFS ou CIFS. Concrètement, ce sera apprécié par ceux qui exécutent des machines virtuelles Windows sur Proxmox VE. Autre évolution : un contrôle plus fin de la virtualisation imbriquée. Grâce à un nouveau flag vCPU, les administrateurs peuvent activer précisément les extensions nécessaires aux hyperviseurs imbriqués ou aux systèmes exploitant la Virtualization-based Security (VBS). "Cette option flexible offre aux administrateurs informatiques davantage de contrôle et constitue une alternative optimisée à la simple exposition du type de processeur hôte complet à l'invité.", précise Proxmox. Une observabilité SDN enrichie pour les infrastructures complexes Le communiqué de Proxmox précise aussi que Proxmox VE 9.1 améliore la stack SDN, en proposant une interface beaucoup plus détaillée pour la supervision réseau. Le tableau de bord de Proxmox VE permettra d'identifier plus facilement l'ensemble des invités (VM, conteneurs) connectés à un pont ou à un vNet. "L'interface graphique mise à jour offre une visibilité sur les composants clés du réseau, tels que les VRF IP et les VRF MAC.", précise le document. Proxmox VE 9.1 est basé sur Debian 13.2 Alors que Proxmox VE 9 est basé sur Debian 13, cette nouvelle version est basée sur Debian 13.2. Comme l'explique la documentation de Proxmox, d'autres paquets importants ont été mis à jour, tout comme le noyau Linux qui passe en version 6.17.2-1. QEMU 10.1.2 LXC 6.0.5 ZFS 2.3.4 Ceph Squid 19.2.3 Qu'en pensez-vous ? Envie d'apprendre à utiliser Proxmox VE ? Commencez par lire mon guide pour bien débuter : Débuter avec Proxmox VE : installation et premiers pas Mise à niveau de Proxmox VE 8 vers 9 Source Afficher l’article complet -
Proxmox Proxmox VE - La gestion des snapshots sur les VM - IT-Connect
Ldfa a posté un sujet dans Mon Wallabag
durée de lecture : 7 min Parmi les fonctionnalités offertes par Proxmox VE pour gérer les machines virtuelles et les conteneurs, il y a les snapshots et les sauvegardes. Bien que ces deux fonctionnalités soient associées à la protection des données, elles servent des objectifs distincts et fonctionnent différemment. Cet article fait un focus sur les snapshots avec les machines virtuelles Proxmox, mais il me semble important d'y associer un rappel sur les différences entre les snapshots et les sauvegardes (backup). Cliquez ici pour regarder la vidéo sur YouTube Il y a parfois une certaine confusion entre les snapshots et les backups, et pourtant, les intérêts de ces deux fonctionnalités sont différents. Snapshots (Instantanés) Un snapshot dans Proxmox VE est une capture de l'état d'une VM ou d'un conteneur à un moment précis. Son principal objectif est de créer un point de restauration rapide afin de pouvoir revenir en arrière (ou naviguer entre plusieurs états). Lorsque vous prenez un snapshot, Proxmox VE enregistre la configuration de la VM à ce moment-là. Ensuite, toutes les modifications ultérieures de la VM sont écrites dans un nouveau fichier, tandis que les données d'origine restent inchangées, permettant ainsi de revenir rapidement à l'état capturé. En général, ces données sont stockées dans le même répertoire que les données de la machine virtuelle en elle-même. L'objectif principal est de pouvoir revenir rapidement à un état antérieur en cas de problème (par exemple, après une mise à jour logicielle ratée, une modification de configuration risquée ou pour des tests). Le snapshot a vocation à être temporaire. Backups (Sauvegardes) Une sauvegarde est une copie complète et autonome des données et de la configuration d'une VM ou d'un conteneur à un moment donné. Pour réaliser ses sauvegardes, Proxmox VE s'appuie l'outil de sauvegarde intégré : vzdump, à ne pas confondre avec la solution Proxmox Backup Server. Cet outil crée une archive complète des données de la ressource (machine virtuelle ou snapshot), y compris les fichiers de configuration. La sauvegarde, quant à elle, est de préférence stockée sur un espace de stockage externe (NAS ou autre). L'objectif principal est d'assurer la récupération après sinistre (perte de données, erreur système critique, etc.) ou l'archivage à long terme. Une sauvegarde, contrairement à un snapshot, est associé à une stratégie de rétention. Pour commencer, nous verrons comment créer, modifier, restaurer et supprimer un snapshot à partir de l'interface web (GUI) de Proxmox VE. Ce sera l'occasion de voir la mécanique de fonctionnement des snapshots en prenant un exemple. Avant de commencer, voici une précision associée au format du disque et la compatibilité avec les snapshots : Le format qcow2 (QEMU image format) prend en charge nativement les snapshots de l'image disque. Le format raw (image disque brute) ne prend pas en charge les snapshots par lui-même, donc il nécessite que la couche de stockage gère cette fonctionnalité. Autrement dit, dans certains cas, il se peut que les snapshots ne soient pas possibles ! Vous pouvez consulter le tableau sur cette page, il offre une bonne vue d'ensemble. Nous allons voir comment créer un snapshot d'une VM Proxmox. Actuellement, nous avons l'état suivant : une machine Debian 12 sur laquelle Apache2 n'est pas installé. Avant de procéder à l'installation, et pour avoir la possibilité de revenir en arrière, nous allons faire un snapshot. Voici les étapes à suivre : 1. Connectez-vous à votre interface web Proxmox VE. Dans l'arborescence des ressources à gauche, sélectionnez le nœud sur lequel la VM est hébergée. 2. Sélectionnez la VM pour laquelle vous souhaitez créer un snapshot, ici c'est la VM avec l'ID 100. 3. Dans le menu dédié à la VM, cliquez sur "Snapshots" puis sur le bouton "Take Snapshot". Une boîte de dialogue s'ouvrira. Vous devez alors saisir un nom, par exemple Snap1-20250723-Avant-Apache et une description. Sachez que vous pouvez créer plusieurs snapshots pour une même VM. Lors de la création d'un instantané sur une machine virtuelle, il y a une option nommée "Include RAM". Cochez cette option si vous souhaitez que le snapshot inclue l'état de la mémoire vive de la VM. Cela permet de restaurer la VM exactement dans l'état où elle se trouvait au moment du snapshot, sans nécessiter un démarrage complet. Cliquez sur "Take Snapshot" pour confirmer. La création du snapshot est un succès, comme le prouve le message TASK OK dans la sortie. Désormais, l'état actuel (NOW) est positionné sous notre snapshot, puisque ce dernier correspond à un état antérieur. La date et l'heure à laquelle le snapshot a été créé est clairement spécifiée, ce qui est une information essentielle. Vous pouvez éditer un snapshot à tout moment, ce sera l'occasion de modifier sa description. Toujours sur ce même machine Debian 12, j'ai pu procéder à l'installation d'Apache2. Mais, finalement, j'aimerais revenir en arrière. Je pourrais prendre le temps de supprimer le paquet et nettoyer le système. Néanmoins, nous allons simplement restaurer le snapshot pour revenir à l'état antérieur. Suivez ces étapes : 1 - Toujours dans la gestion de la VM, cliquez sur "Snapshots" 2 - Sélectionnez le snapshot à restaurer. 3 - Cliquez sur le bouton d'action nommé "Rollback". 4 - Cliquez sur "Yes" pour valider. Attention, les modifications effectuées après l'état capturé dans l'instantané seront perdues. Patientez le temps de l'opération. À partir de là, le snapshot a été restauré, mais il est toujours présent. Si vous n'en avez plus besoin, il conviendra de le supprimer. J'en profite pour évoquer la possibilité de créer plusieurs snapshots. Vous pouvez ensuite naviguer entre les différents états. Ce qui est important, c'est le positionnement du pointeur "NOW". Ici, nous pouvons voir que l'état actuel est basé sur le snapshot Snap1, et non sur le Snap2. Avec ce second exemple, l'état actuel est basé sur le Snap2. Nous n'avons plus besoin de notre snapshot, alors il est temps de le supprimer. En effet, le snapshot peut avoir un impact sur les performances et aussi augmenter la consommation sur l'espace de stockage. N'oublions pas qu'il a vocation à être temporaire. Pour supprimer un snapshot, procédez toujours depuis la section "Snapshots" de la ressource. Vous devez simplement sélectionner le snapshot à supprimer et cliquez sur le bouton "Remove". Confirmez l'opération. Dans la suite de ce tutoriel, nous allons basculer en ligne de commande pour effectuer la gestion des snapshots sur une machine virtuelle. Avant de commencer, vous devez accéder à ce terminal, soit via l'interface web de Proxmox VE ou en connexion SSH directe. 1 - Cliquez sur votre nœud PVE sur la gauche. 2 - Sélectionnez "Shell" dans le menu et connectez-vous avec votre compte. 3 - Vous pouvez lister vos machines virtuelles avec la commande qm list. Vous devez utiliser la commande qm snapshot pour créer un snapshot. Celle-ci attend plusieurs informations comme l'ID de la VM et le nom du snapshot. La syntaxe à adopter est la suivante : qm snapshot <VMID> <NOM_DU_SNAPSHOT> [OPTIONS] Donc, pour créer un snapshot sur la VM avec l'ID 100, nommer ce snapshot Snap-avec-Shell et lui ajouter une description, tout en capturant l'état de la RAM, il conviendra d'exécuter cette commande : qm snapshot 100 Snap-avec-Shell --description "Snapshot créé depuis le Shell Proxmox" --vmstate true Vous pouvez ensuite lister les snapshots de cette VM : qm listsnapshot 100 Bien entendu, sur l'interface web de Proxmox, cet instantané est visible : Pour restaurer le snapshot que nous venons de créer, nous devons utiliser la commande qm rollback de cette façon : qm rollback <VMID> <NOM_DU_SNAPSHOT> Dans notre cas, la commande serait donc : qm rollback 100 Snap-avec-Shell Enfin, si nous n'avons plus besoin de ce snapshot, nous pouvons le supprimer avec une autre commande prévue à cet effet : qm delsnapshot. Elle s'utilise sur le même principe que la commande pour le rollback : qm delsnapshot <VMID> <NOM_DU_SNAPSHOT> Dans le cas présent, nous devons exécuter cette commande : qm delsnapshot 100 Snap-avec-Shell Logical volume "vm-100-state-Snap-avec-Shell" successfully removed. Logical volume "snap_vm-100-disk-0_Snap-avec-Shell" successfully removed. En suivant ce tutoriel, vous êtes en mesure de créer, restaurer et supprimer les snapshots sur les machines virtuelles (et les conteneurs) hébergés sur Proxmox VE. Vous pouvez procéder via l'interface web ou la ligne de commande, selon vos besoins. La ligne de commande est plus intéressante lorsqu'il y a des tâches à automatiser. Afficher l’article complet
-
durée de lecture : 2 min Jamais le patron de Microsoft n’avait rencontré Linus Torvalds de Linux. Il y a vingt ans, leur rivalité démontrait le choc de deux visions dans la nouvelle ère Internet : le logiciel propriétaire et l’open source. Bill Gates et Linus Torbalds, sur la même photo, partageant leur premier déjeuner ensemble. Le 22 juin, le fondateur de Microsoft et le programmateur finlandais surnommé le « père » de Linux sont apparus publiquement pour la première fois de leur vie côte à côte, une image plus que symbolique, qui rassemble deux visions et deux fondations de l’Internet que l’on connaît. Tous les deux passionnés d’informatique, ils représentent d’un côté la suite de logiciels propriétaires et de l’autre le mouvement open source. La rencontre a pris place lors d’un déjeuner, organisé chez Mark Russinovich, le directeur technique de Microsoft Azure. C’est lui qui a d’ailleurs posté la photo sur le réseau LinkedIn (racheté par Microsoft il y a dix ans). À leurs côtés, un autre convive, tout aussi important du Microsoft des années 1990 : David Cutler, l’une des figures centrales de Windows NT. Il y a vingt ans, Microsoft voyait Linux comme son ennemi principal, une vraie menace. Aujourd’hui, leurs fondateurs se rencontrent, et Microsoft est moins fermé à l’open source, alors que le géant américain détient GitHub. « J’ai eu le frisson de ma vie en organisant un dîner pour Bill Gates, Linus Torvalds et David Cutler », écrivait Mark Russinovich sur son post. Aujourd’hui, les principaux chefs d’entreprise technologiques américains ont l’habitude de se côtoyer dans des événements, tels que des conférences, des soirées people, mais aussi des auditions au Sénat. Il y a vingt ans, jamais Bill Gates et Linus Torbalds ne s’étaient affichés en public. Depuis, Mark Russinovich avançait que les deux hommes ne s’étaient effectivement jamais rencontrés. Si Bill Gates avait un problème avec Linux, Linus Torbalds en avait aussi un avec Microsoft. Il critiquait souvent l’entreprise en soulignant ses pannes. Lire aussi Bill Gates publie son CV, rédigé il y a 48 ans, juste avant la création de Microsoft Alors que le déjeuner a suscité un vif intérêt au sein de la communauté technologique, Mark Russinovich n’a rien arrangé, en déclarant qu’une nouvelle rencontre pourrait avoir lieu, et que des projets pourraient en découler entre les deux hommes, aujourd’hui âgés de 69 ans pour l’Américain et de 55 ans pour le Finlandais. « Linus n’a jamais rencontré Bill, et Dave (David) n’a jamais rencontré Linus. Aucune décision majeure n’a été prise ici, mais peut-être lors du prochain dîner », a-t-il écrit sur son poste sur LinkedIn. 🔴 Pour ne manquer aucune actualité de 01net, suivez-nous sur Google Actualités et WhatsApp. Afficher l’article complet
-
durée de lecture : 9 min Surveiller et comprendre les logs serveur Linux est une compétence essentielle pour tout administrateur système. Que ce soit pour diagnostiquer un problème au démarrage ou auditer les connexions SSH, les logs de démarrage Linux et les logs de connexion Linux offrent une mine d’informations précieuses. Grâce à des outils comme journalctl ou en consultant des fichiers tels que /var/log/auth.log, vous pouvez facilement repérer les tentatives de connexion échouées, détecter des comportements anormaux ou encore assurer la sécurité de votre serveur Linux. Dans ce tutoriel, nous allons voir comment analyser les logs de démarrage et de connexion, quels fichiers et commandes utiliser, et quelles bonnes pratiques adopter pour l’analyse des logs Linux. Que vous soyez débutant ou administrateur expérimenté, cet article vous donnera toutes les clés pour maîtriser l’analyse des logs sur un serveur Linux. Sommaire de l'article 1 Comprendre les logs serveur Linux et leur rôle essentiel 1.1 Importance des logs pour la sécurité et le diagnostic 1.2 Emplacement des fichiers de logs principaux 2 Analyser les logs de démarrage 2.1 Utilisation de journalctl pour les logs de démarrage 2.2 Commande Last et fichier wtmp 2.3 Interprétation des messages de démarrage 3 Sécuriser votre système grâce à l’analyse des logs serveur Linux 3.1 Analyse de /var/log/auth.log pour les connexions SSH 3.2 Détection des tentatives de connexion échouées 4 Mettre en place la rotation de fichier log 5 FAQ – Analyse des logs de démarrage et de connexion sur un serveur Linux Comprendre les logs serveur Linux et leur rôle essentiel Importance des logs pour la sécurité et le diagnostic Les logs système sous Linux jouent un rôle essentiel dans la gestion, le diagnostic et la sécurité d’un serveur. Ils permettent de retracer les événements du système, d’identifier des erreurs au démarrage, de surveiller l’activité des utilisateurs et de détecter d’éventuelles tentatives de connexion non autorisées. Une bonne maîtrise de l’analyse des logs permet de réagir rapidement face à un dysfonctionnement ou une menace de sécurité. En consultant régulièrement les logs de démarrage Linux et les logs de connexion Linux, un administrateur peut anticiper les problèmes et renforcer la sécurité du serveur Linux. Emplacement des fichiers de logs principaux Sous Linux, la majorité des fichiers de logs sont stockés dans le répertoire /var/log. Voici quelques-uns des fichiers les plus utilisés pour l’analyse : /var/log/syslog ou /var/log/messages : contiennent des informations générales sur le système. /var/log/auth.log (Debian/Ubuntu) ou /var/log/secure (CentOS/RHEL) : enregistrent les connexions SSH, les authentifications et les tentatives échouées. /var/log/dmesg : stocke les messages du noyau au démarrage. /var/log/boot.log : affiche les messages relatifs à la séquence de démarrage. /var/log/faillog et /var/log/lastlog : utiles pour suivre les échecs d’authentification et les dernières connexions. Pour une vision consolidée des événements, l’outil journalctl, utilisé avec systemd, permet de consulter l’ensemble des logs système de manière centralisée et filtrée, notamment ceux liés au démarrage et aux connexions utilisateur. Analyser les logs de démarrage Utilisation de journalctl pour les logs de démarrage Sous les distributions Linux utilisant systemd, la commande journalctl est l’outil principal pour consulter les logs de démarrage Linux. Elle permet d’extraire toutes les informations liées à la séquence de démarrage, depuis le moment où le noyau est chargé jusqu’au lancement complet du système. Pour visualiser les logs du dernier démarrage, on peut utiliser la commande : journalctl -b Vous pouvez également filtrer par niveau de gravité (erreur, avertissement, etc.) ou par unité systemd spécifique. Cela permet de diagnostiquer rapidement les lenteurs de démarrage ou les services défaillants sur votre serveur Linux. Commande Last et fichier wtmp Sous Linux, la commande last permet de lire le contenu des fichiers /var/log/wtmp et /var/log/btmp. Pour connaître les dates et heures ou la machine s’est arrêtée il suffit de taper la commande : #last –x shutdown --time-format iso Les différents shutdown, sont classés du plus récent au plus vieux. Le paramètre –time-format iso permet d’ajouter des informations comme l’année par exemple et à un format de date plus lisible, du moins pour ma part. Pour connaître les dates et heures ou la machine a rebooté, il suffit de taper la commande : #last –x reboot --time-format iso Nous voyons ici que le denier reboot date du 1 mai 2025 à 19h25. Information!!! Le paramètre –x permet d’afficher également les arrêts du système et les modifications de niveau d’exécution (run level). Le fichier wtmp contient une trace de toutes les connexion et déconnexions du système (arrêt, reboot). Le fichier btmp contient tous les échecs de connexions à votre système. Il est impossible de lire directement ces fichiers avec un éditeur de texte type vi ou vim. Voici un exemple avec le fichier btmp : Ah oui, pas facile pour récupérer les informations. Pour lire le fichier de façon plus agréable, vous devez utiliser la commande suivante (vous pouvez utiliser la même commande pour le fichier wtmp): #last –f /var/log/btmp 1: login utilisé pour se connecter à votre machine. 2: type de connexion utilisée, ici ssh 3: adresse ip du hackeur 4: date de tentative de connexion Comme vous pouvez le constater ici l’ip 185.227.152.113 effectue de la brute force pour récupérer un accès sur ma machine. Interprétation des messages de démarrage Les messages de démarrage fournissent des indications précieuses sur le bon fonctionnement des différents composants du système. Ils incluent notamment : Le chargement du noyau et des modules, La détection du matériel, Le montage des systèmes de fichiers, Le démarrage des services systemd. Il est essentiel d’identifier les messages d’erreur (souvent signalés par Failed ou Error) qui peuvent ralentir ou bloquer le démarrage du serveur. De même, les messages comme Job running, Timeout, ou Dependency failed indiquent des problèmes de dépendances ou de services mal configurés. Une analyse régulière des logs de démarrage permet de s’assurer que le système reste stable et performant, et d’intervenir rapidement en cas d’anomalie. Sécuriser votre système grâce à l’analyse des logs serveur Linux Analyse de /var/log/auth.log pour les connexions SSH L’un des fichiers les plus importants pour suivre l’activité des connexions SSH sur un serveur Linux est le fichier /var/log/auth.log (ou /var/log/secure sur CentOS/RHEL). Il enregistre toutes les tentatives d’authentification, qu’elles soient réussies ou échouées, ainsi que les élévations de privilèges via sudo. Pour examiner ces logs de connexion Linux, vous pouvez utiliser une commande comme : grep sshd /var/log/auth.log Cela vous permettra d’identifier quels utilisateurs se sont connectés, à quel moment, depuis quelle adresse IP, et s’ils ont été authentifiés avec succès. Cette analyse est essentielle pour auditer les connexions SSH et maintenir la traçabilité des accès sur votre serveur. Détection des tentatives de connexion échouées Les tentatives de connexion échouées sont des indicateurs clés d’une éventuelle tentative d’intrusion. Elles apparaissent souvent dans les logs sous la forme : Failed password for invalid user ... Pour extraire rapidement ces événements, vous pouvez utiliser : grep "Failed password" /var/log/auth.log ou, pour une vue plus synthétique : awk '/Failed password/ {print $(NF-3)}' /var/log/auth.log | sort | uniq -c | sort -nr Cela vous permet de repérer les adresses IP à l’origine de plusieurs échecs, et de mettre en place des contre-mesures (comme fail2ban ou des règles de pare-feu) pour renforcer la sécurité de votre serveur Linux. La surveillance proactive des logs SSH permet non seulement de détecter les attaques en cours, mais aussi d’identifier les failles potentielles dans la configuration du serveur ou dans les pratiques des utilisateurs. Mettre en place la rotation de fichier log Il vous est possible de définir la durée de conservation de ces logs. Pour ce faire vous devez éditer le fichier /etc/logrotate.conf. Ce qui nous intéresse ici se sont les lignes surlignées en jaune. Voici quelques explications de ces lignes : monthly : La rotation s’effectuera tous les mois. Nous pouvons aussi mettre daily pour tous les jours, weekly pour toutes les semaines. create 0664 root utmp : Les fichiers secondaire créés auront pour créateur root et appartienne au groupe utmp et auront les droits 664. minsize : demande la rotation des log si le fichier fait au minimum la taille définie par cette variable. size : les fichiers ne sont archivés que si leur taille dépasse la valeur définie ici. rotate 1 : Nous garderons 1 fichiers de log missingok : signifie que l’absence du/des fichier(s) log(s) n’est pas anormale. Si cette option n’est pas active alors l’administrateur recevra un mail si le/les log(s) est/sont manquant(s). D’autres paramètres existent comme : compress : Les fichiers logs secondaire c’est à dire tout ce qui n’est pas le fichier de log principal seront compressés. delaycompress : Reporte la compression du journal précédent au prochain cycle de permutation. Ceci n’a un effet qu’utilisé en combinaison avec l’option compress. Elle peut être utilisée quand il n’est pas possible de demander à un programme de fermer son journal et qu’il puisse par conséquent continuer à écrire pour un moment dans le journal précédent. notifempty : permet de ne pas permuter le journal lorsqu’il est vide prerotate, postrotate/endscript : Les lignes entre prerotate et endscript (chacun devant apparaître sur une ligne isolée) seront exécutées avant permutation du journal. Ces directives doivent apparaîtrent dans la définition d’un journal Pour connaître les autres options vous pouvez consulter le man à cette adresse : man logrotate. Afin d’avoir un peu d’historique, j’ai configuré la rotation de cette manière : Dans l’exemple ci-dessus, la rotation s’effectue au bout d’un an à moins que la taille du fichier atteigne les 15 Mo. Par défaut (les cinq premières lignes), la durée de rotation est d’une semaine et la conservation sur 1 mois (rotate 4). Une fois la configuration de votre logrotate terminé, vous pouvez forcer sont exécution de cette manière : #logrotate -f /etc/logrotate.conf ou pour débugger : #logrotate -d /etc/logrotate.conf Si vous souhaitez découvrir d’autres commandes ou astuces pratiques sous Linux, vous pouvez consulter ce tutoriel : Optimiser et dépanner un serveur Linux. FAQ – Analyse des logs de démarrage et de connexion sur un serveur Linux Comment accéder aux logs de démarrage sur un serveur Linux ? Vous pouvez consulter les logs de démarrage Linux en utilisant la commande journalctl -b. Cette commande affiche tous les messages du journal générés depuis le dernier démarrage du système. Pour analyser un démarrage précédent, utilisez journalctl -b. Où trouver les logs de connexion SSH sur Linux ? Les logs de connexion Linux, notamment ceux liés à SSH, sont généralement stockés dans le fichier /var/log/auth.log (sur les distributions Debian/Ubuntu) ou /var/log/secure (sur CentOS/RHEL). Ces logs permettent de suivre les connexions réussies et échouées. Comment détecter les tentatives de connexion échouées ? Vous pouvez utiliser la commande suivante pour repérer les tentatives échouées dans le fichier de log : grep "Failed password" /var/log/auth.log C’est utile pour auditer les connexions SSH et identifier d’éventuelles attaques par force brute. Quels outils permettent d’analyser les logs sous Linux ? En plus de journalctl, vous pouvez utiliser des outils comme : logwatch : pour générer des rapports quotidiens des logs. logrotate : pour gérer l’archivage des logs. Des solutions comme ELK Stack ou Loggly pour une analyse avancée des logs Linux avec visualisation. Pourquoi est-il important de surveiller les logs serveur Linux ? L’analyse régulière des logs permet de : Identifier rapidement des erreurs système ou des problèmes de configuration. Détecter des tentatives d’intrusion ou des connexions suspectes. Maintenir un haut niveau de sécurité sur le serveur Linux. Afficher l’article complet
-
Vu sur le Shaarli de SebSauvage : Source : https://sebsauvage.net/links/?uzjm5A
-
Une nouvelle invitation de traduction française de Maxthon Cloud pour Linux vient de me parvenir et je suppose que comme les fois précédentes, vous devriez pouvoir y participer en cliquant sur le lien suivant : https://crowdin.net/project/maxthon-for-linux/invite?d=9525i4j675v6c563m4a393f3 Voici le courriel de Sasha que je viens de recevoir :