Toute l’activité
- Dernière heure
-

Anniversaire Anniversaire du site : 22 ans déjà !!!
Ldfa a posté un sujet dans Nouveautés du Site Maxthon-fr.com
J'ai encore une fois raté la date de l'anniversaire du site, c'était le 14 février 2025 pour ses 22 ans d'existence... Il faut vraiment que je crée un rappel sur mon agenda. Même s'il y a beaucoup moins de visiteurs et de nouveautés du côté de Maxthon, le site est toujours en ligne et il compte tout de même un petit nombre d'utilisateurs habitués et fidèles depuis toutes ces années, un grand à. eux pour leur présence et leur participation. -
 franz a réagi à un message dans un sujet :
Windows : comment capturer l’activité au démarrage de l'OS ? - IT-Connect
franz a réagi à un message dans un sujet :
Windows : comment capturer l’activité au démarrage de l'OS ? - IT-Connect
-

Windows : comment capturer l’activité au démarrage de l'OS ? - IT-Connect
Alex a répondu à un(e) sujet de Ldfa dans Mon Wallabag
Merci Boss ! Ca fait un moment que j'apprécie les outils SysInternal. Chez moi il sont bien rangés dans un répertoire au coté des outils Nirsoft et Sordum. Et puis je pense jamais à les utiliser. ProcMon, j'avais jeté un oeil y'a 4/5 ans et j'avais dû trouver ça trop compliqué, j'avais oublié. Mais ton article va m'inciter à aller voir ça de plus près, ça à l'air puissant. -
Alex a réagi à un message dans un sujet :
Windows : comment capturer l’activité au démarrage de l'OS ? - IT-Connect
- Aujourd’hui
-
Windows : comment capturer l’activité au démarrage de l'OS ? - IT-Connect
Ldfa a posté un sujet dans Mon Wallabag
durée de lecture : 4 min Dans ce tutoriel, nous vous montrons comment capturer et analyser l’activité au démarrage de Windows. Nous utiliserons pour cela l’outil ProcMon des Sysinternals. Capturer l’activité au démarrage de Windows peut avoir plusieurs intérêts. Par exemple, l'identification des logiciels et services qui s'exécutent automatiquement, la surveillance de l'activité réseau des processus ou l'investigation des plantages spécifiques. Cependant, cette tâche présente un défi majeur : la plupart des outils d'analyse ne peuvent être lancés qu'après l'ouverture d'une session utilisateur. Heureusement pour nous, ProcMon propose une solution grâce à son option de journalisation au démarrage. ProcMon est un outil de monitoring qui permet de tracer, enregistrer et analyser avec une grande précision les activités de tous les processus au niveau du système de fichier, des registres, des processus/threads et du réseau. Si vous souhaitez avoir une présentation plus détaillée de cet outil, que nous allons utiliser ici, je vous oriente vers notre article d’introduction : L’introduction de cet outil officiel de Microsoft étant faite, passons à l’action ! Une fois que ProcMon est sur votre système de fichier et que vous disposez d’un accès administrateur (obligatoire), nous allons l’exécuter afin d’avoir la vue suivante : Vue principale de ProcMon. Ici, il faut nous rendre dans Options, puis cocher Enable Boot Logging (littéralement : Activer la journalisation du démarrage) : Activation de la journalisation des activités au démarrage par Procmon. L’activation de cette option fait apparaitre la fenêtre suivante : Choix de la surveillance du thread profiling. L'activation de cette option Generate thread profiling est un cas d'utilisation avancé. Lorsque activé, ProcMon fait une capture avancée de l’utilisation des threads et de l'utilisation du processeur, ce qui vous permet d'identifier la source des problèmes de performances liés au processeur. Vous pouvez l’ignorer, à moins de savoir exactement que c’est cela dont vous avez besoin. Bref, il suffit de cliquer sur OK, et c’est tout ! Vous pouvez à présent redémarrer votre système. Pour être plus précis, lorsque l’on active le Boot Logging dans ProcMon, un pilote de filtre (Filter drivers) est installé au niveau du noyau du système d'exploitation. Ce pilote peut capturer les événements liés aux fichiers, aux registres, aux processus et aux threads. Il est conçu pour surveiller les appels système et les interactions à un niveau bas. Le pilote de ProcMon est principalement passif et enregistre les événements sans intervenir dans leur exécution. Une fois votre système redémarré, vous ne devriez pas voir de grandes différences. Cependant, vous trouverez dans le répertoire C:\Windows un fichier nommé Procmon.pmb : Fichier d'enregistrement des activités depuis le démarrage de ProcMon. C’est dans ce fichier que sont stockés les évènements capturés depuis le démarrage. Tant qu’il n’est pas ouvert par l’intermédiaire de ProcMon, ce dernier continuera de capturer des évènements. Sans toucher directement à ce fichier, nous pouvons à présent exécuter ProcMon (toujours en tant qu’utilisateur privilégié). Dès lors, le message suivant apparaitra : Message de confirmation pour l’enregistrer des données capturées. Il indique que ProcMon a trouvé son fichier de capture et vous demande si vous souhaitez arrêter la capture et enregistrer les évènements capturés. En cliquant sur OK, ProcMon ouvrira l’explorateur de fichier pour que vous puissiez enregistrer la capture, cette fois-ci au format PML. Dans mon cas, je l’enregistre, par exemple, dans C:\Users\Administrateur\Desktop. Une petite barre de progression va alors apparaitre, c’est l’enregistrement des activités qui est en cours (en général, il y en a beaucoup). Le contenu du fichier va s’afficher dans l’interface d’analyse et de filtre de ProcMon. Vous pourrez ensuite visualiser la totalité des évènements qui se sont produits du démarrage du système d’exploitation, jusqu’à l'enregistrement de la capture que nous venons de réaliser : Exemple des premières activités capturées par ProcMon. Tout l’intérêt d’utiliser ProcMon est ensuite bien sûr d’utiliser ses filtres et sa grande précision pour réaliser vos propres recherches et investigations. Pour en savoir plus sur ces filtres et le niveau de détails qu’il est possible d’obtenir, je vous renvoie à nouveau vers notre article dédié à l’utilisation de ProcMon : La possibilité d’enregistrer ces activités dans un fichier (format .PML) est intéressant pour l’historisation et la comparaison de deux captures, ou pour pouvoir revenir dessus plus tard si besoin. L'utilisation de ProcMon pour capturer l'activité au démarrage de Windows est très utile pour diagnostiquer les problèmes de performance et identifier les logiciels ou services qui s'exécutent dès le démarrage. En activant le Boot Logging, ProcMon enregistre toutes les interactions système, permettant une analyse détaillée grâce à ses filtres. Une astuce à garder en tête pour les cas difficiles ! N’hésitez pas à partager votre avis dans les commentaires ou à venir échanger avec notre communauté sur notre serveur Discord ! Afficher l’article complet
-
Formation à l'Administration de serveurs Linux - Stéphane ROBERT
Ldfa a posté un sujet dans Mon Wallabag
durée de lecture : 8 min Linux est aujourd’hui omniprésent dans le monde des serveurs et des infrastructures IT. Ce système d’exploitation libre et open source alimente une majorité des serveurs web, des supercalculateurs, des infrastructures cloud et même des équipements embarqués. Que ce soit pour héberger un site web, gérer des services réseau ou déployer des applications critiques, Linux s’est imposé comme un choix incontournable grâce à sa stabilité, sa flexibilité et sa sécurité. Dans cette formation, vous découvrirez non seulement comment utiliser Linux efficacement, mais surtout comment l’administrer en toute autonomie. Vous apprendrez à maîtriser les commandes essentielles, à configurer le réseau, à gérer la sécurité de votre système et à surveiller ses performances. Vous serez également guidé dans la mise en œuvre de bonnes pratiques pour l’écriture de scripts shell, la gestion des utilisateurs, ou encore la planification des tâches automatiques. Pourquoi cette formation Linux Gratuite ? Parce qu’aujourd’hui, comprendre le fonctionnement d’un système Linux est indispensable pour toute personne souhaitant évoluer dans les métiers de l’administration système ou se préparer à des rôles orientés DevOps. Vous ne vous contenterez pas d’apprendre à utiliser Linux : vous saurez le configurer, le sécuriser et l’optimiser. À qui s’adresse cette formation Linux ? Cette formation Linux s’adresse à toute personne souhaitant acquérir des compétences en administration système Linux, que vous soyez : Administrateur système débutant souhaitant structurer vos connaissances ; Développeur cherchant à comprendre l’environnement dans lequel vos applications tournent ; Étudiant ou autodidacte préparant une certification comme la LFCS ; Ou encore un professionnel de l’IT désirant élargir votre champ de compétences en vue d’une spécialisation DevOps. Pour suivre cette formation dans de bonnes conditions, il est conseillé d’avoir : Des bases en informatique générale (utilisation du terminal, notions sur les systèmes d’exploitation) ; Une curiosité technique et une volonté d’expérimenter par vous-même. Vous n’avez jamais administré de serveur ? Aucun problème : cette formation a été conçue pour partir des fondamentaux. Vous avez déjà des notions mais souhaitez approfondir vos pratiques ? Les sections avancées vous permettront d’aller plus loin, notamment sur la gestion de la sécurité, la surveillance système ou l’optimisation des performances. Organisation de la formation Linux Cette formation a été pensée pour vous offrir un parcours progressif et pratique, articulé autour de plusieurs grands principes : 1. Cours théoriques détaillés Chaque chapitre aborde une thématique clé de l’administration Linux : commandes essentielles, gestion des fichiers, réseau, sécurité, optimisation… Les contenus sont illustrés d’exemples concrets et enrichis de liens vers des ressources externes pour aller plus loin. 2. Travaux pratiques avec auto-évaluation Pour chaque compétence, des travaux pratiques vous permettent d’appliquer directement ce que vous venez d’apprendre. Vous serez invité à reproduire des scénarios réels : configurer un réseau, écrire un script shell sécurisé ou encore surveiller les performances d’un serveur. Ces TP sont accompagnés de systèmes d’auto-évaluation pour valider votre progression en autonomie. 3. Contrôles réguliers des connaissances Afin de mesurer vos acquis, des quiz et contrôles de connaissances ponctuent la formation. Ces évaluations rapides vous aident à vérifier que vous avez bien assimilé les notions clés avant de poursuivre. 4. Une durée flexible selon votre rythme La durée de cette formation est estimée entre 40 et 50 heures, en fonction de votre niveau de départ et de votre implication personnelle. Vous pouvez choisir de suivre le parcours de façon intensive ou de le répartir sur plusieurs semaines selon vos disponibilités. 5. Un tremplin vers le DevOps En suivant ce programme complet, vous poserez les fondations essentielles pour évoluer ensuite vers des pratiques DevOps : gestion d’infrastructure automatisée, CI/CD, orchestration avec des outils comme Docker ou Kubernetes. Cette formation est donc une étape indispensable pour toute personne visant une carrière dans ces domaines. Programme de la formation Linux Le programme de cette formation Linux a été soigneusement structuré pour vous accompagner pas à pas dans la découverte et la maîtrise des compétences essentielles à l’administration d’un serveur Linux. Chaque section aborde des thématiques clés : des bases fondamentales jusqu’aux notions avancées du noyau, en passant par la configuration réseau, la gestion des utilisateurs, les services système, ou encore la sécurisation et l’optimisation des performances. Notions fondamentales sur Linux Installation des serveurs Linux Installation de WSL2 Maîtriser les shells Linux : Introduction Le Shell Bash Le Shell Zsh Commandes Linux : Introduction aux commandes Linux Commandes d’arrêt et redémarrage Navigation & Manipulation de Fichiers Commandes avancées Gestion des processus Gestion de la mémoire Gestion des archives Gestion des périphériques Gestion du réseau Commandes de référence : awk de A à Z curl de A à Z find de A à Z grep de A à Z parallel de A à Z rsync de A à Z sed de A à Z tar de A à Z xargs de A à Z Édition de fichiers : Nano - L’éditeur de texte Vi - L’éditeur de texte Vim - Un vi amélioré Développement de scripts Shell : Développer des scripts Shell Écrire des scripts Shell sécurisés Configurer un serveur Linux : Introduction Configurer les utilisateurs et groupes Comprendre et configurer sudo Gérer les ACL Gestion des packages : Introduction APT : Debian/Ubuntu APK : Alpine Linux DNF : RedHat et dérivés Pacman : Arch Linux Zypper : Suse Configurer le stockage : Introduction Types de systèmes de fichiers : Introduction ext4 Btrfs XFS Gestion des disques locaux : Introduction Identifier les disques Gérer les partitions Monter/Démonter des partitions LVM - Gestion des volumes logiques Gérer l’espace disque Gérer les quotas Analyser les performances des disques Stockage en réseau : Configurer le réseau : Comprendre le réseau Linux Configurer avec Netplan Configurer avec NetworkManager Configurer le pare-feu : Introduction Firewalld UFW Configurer les services : Qu’est-ce-que Systemd ? Gestion des services avec systemctl Logs avec journalctl Gestion des logs avec logrotate Planification de tâches : Avec cron Avec systemd timers Optimisation des performances : Optimiser un serveur Linux Connexion SSH et tunneling sécurisé : Connexion SSH Transfert de fichiers avec SCP Tunneling SSH Notions importantes à connaître : Cgroups Namespaces Capabilities Préparer les Certifcations : LFCS Contrôle de connaissances Pour mieux visualiser la structure globale de cette formation, une mindmap est disponible ci-dessous, vous permettant d’avoir un aperçu clair et synthétique de l’ensemble du programme. Voici une rodmap de votre parcours d’apprentissage : LégendesRecommandéAlternatifOptionnel✔️ Choix personnel🖱️ Navigation• Glisser : déplacer• Molette : zoom• Double clic : recentrerLinux Notions fondamentales sur Linux Installation de Linux Installation de Linux Installation via WSL2 Maîtriser les shells Linux Introduction aux Shells Linux Bash Zsh Fish Commandes Linux Commandes de base Commandes d'aideCommandes de navigationManipulation de fichiersGestion des permissionsVisualisation de fichiersCommandes de rechercheGestion des processus man tldr ls cd pwd cp mv rm mkdir rmdir chmod chown chgrp cat less head tail find locate jobs bg fg Commandes avancées Commandes système de fichiersCommandes de gestion des processusCommandes de manipulation de texteCommandes de comparaisonCommandes de surveillance df du free uname ps top kill grep cut sort uniq tr wc paste join comm nl tee rev fold sed awk diff watch Édition de fichiers Éditeur de texte Vi Éditeur de texte Nano Éditeur de texte Vim Éditeur de texte EmacsÉditeur de texte NeovimScripts Shell Écrire ses premiers scripts Shell Écrire des scripts shells sécurisés Configurer un serveur Linux Utilisateurs et groupes Système de fichiers Introduction au système de fichiers ext4 Btrfs XFS LVM Gestionnaire de paquets APT YUM/DNFPacmanZypper APK YAYNix Prêt à vous lancer ? Plongez pour développer une maîtrise complète de l’administration systèmes sous Linux. FAQ - Questions Fréquemment Posées Quelles sont les missions principales d’un administrateur système Linux ? L’administrateur système Linux est responsable de l’installation, la configuration, la maintenance et la sécurisation des serveurs Linux. Il surveille les performances, gère les sauvegardes, automatise les tâches répétitives et assure la disponibilité des services réseau. Quelles compétences clés doit maîtriser un administrateur Linux ? Il doit maîtriser le terminal Linux, la gestion des utilisateurs, la configuration réseau, les systèmes de fichiers, la sécurité (pare-feu, sudo), la surveillance des performances et l’écriture de scripts shell. La connaissance des outils de monitoring et de virtualisation est également importante. Comment débuter dans l’administration système Linux ? Commencez par installer une distribution Linux serveur (Ubuntu, Debian…), entraînez-vous aux commandes de base, apprenez à gérer les services, configurez le réseau et mettez en place des scripts automatisés. Suivre des tutoriels pratiques et préparer une certification type LFCS est recommandé. Comment surveiller efficacement un serveur Linux ? Utilisez des outils natifs comme `top`, `htop`, `vmstat`, `iostat` et `journalctl` pour la surveillance de base. Pour un monitoring avancé, déployez des solutions comme Zabbix, Nagios ou Prometheus afin d’obtenir des alertes et des rapports détaillés. Quelles sont les bonnes pratiques pour sécuriser un serveur Linux ? Mettre à jour régulièrement le système, configurer un pare-feu (UFW, Firewalld), désactiver les services inutiles, utiliser des clés SSH, limiter les droits sudo, surveiller les logs et appliquer la règle du moindre privilège sont des bonnes pratiques essentielles. Pourquoi l’automatisation est-elle essentielle pour un administrateur Linux ? L’automatisation via des scripts shell ou des outils comme Ansible permet de réduire les erreurs humaines, de standardiser les déploiements et de gagner du temps sur les tâches répétitives (sauvegardes, mises à jour, surveillance…). Quelles certifications recommandées pour un administrateur Linux ? Les certifications les plus reconnues sont : LFCS (Linux Foundation Certified System Administrator), LPIC-1, CompTIA Linux+, et RHCSA (Red Hat Certified System Administrator). Elles valident des compétences pratiques recherchées par les employeurs. Quels outils utiliser pour la gestion des services sous Linux ? L’outil principal est `systemctl` (Systemd), qui permet de démarrer, arrêter, redémarrer, activer au démarrage et vérifier le statut des services. Exemple : `systemctl restart apache2`, `systemctl enable ssh`, `systemctl status nginx`. Quelle est la place de Linux dans le DevOps ? Linux est le socle des pratiques DevOps : conteneurs (Docker), orchestration (Kubernetes), intégration continue, infrastructure as code… Tous ces outils reposent sur un environnement Linux, rendant sa maîtrise indispensable pour un rôle DevOps. Quels sont les défis quotidiens d’un administrateur Linux ? Les défis incluent la gestion des incidents, la garantie de la disponibilité des services, l’optimisation des performances, l’application rapide des correctifs de sécurité, la gestion des sauvegardes et la documentation précise des interventions. Afficher l’article complet
- Hier
-
 Ldfa a réagi à un message dans un sujet :
Navigateur Internet CatsXP, la relève de Maxthon ?
Ldfa a réagi à un message dans un sujet :
Navigateur Internet CatsXP, la relève de Maxthon ?
-

Chromium Navigateur Internet CatsXP, la relève de Maxthon ?
ErnestR4 a répondu à un(e) sujet de Ldfa dans Et la famille Webkit alors...
Je suis en train de le tester et les mouvements de la souris peuvent être presque tous régler comme dans Mx7. Il arrive même à traduire rapidement en français les pages des sites anglais alors que dans Mx7 c'est très aléatoire -
durée de lecture : 18 min Temps de lecture 20 min Cet article est une republication, avec l’accord de l’auteur, Hubert Guillaud. Il a été publié en premier le 13 janvier 2025 sur le site Dans Les Algorithmes sous licence CC BY-NC-SA. Hubert Guillaud Des contenus générés par IA qui ânonnent des textes qui ne veulent rien dire. Des images stylisées qui nous déconnectent de la réalité. L’internet zombie colonise l’internet, par un remplissage par le vide qui n’a pas d’autre enjeu que de nous désorienter. Sur la plupart des réseaux sociaux vous avez déjà dû tomber sur ces contenus génératifs, pas nécessairement des choses très évoluées, mais des contenus étranges, qui n’ont rien à dire, qui hésitent entre développement personnel creux, blague ratée ou contenu sexy. Des vidéos qui ânonnent des textes qui ne veulent rien dire. Les spécialistes parlent de slop, de contenus de remplissages, de résidus qui peu à peu envahissent les plateformes dans l’espoir de générer des revenus. A l’image des contenus philosophiques générés par l’IA que décortique en vidéo Monsieur Phi. IA slop : de la publicité générative à l’internet zombie Pour l’instant, ces contenus semblent anecdotiques, peu vus et peu visibles, hormis quand l’un d’entre eux perce quelque part, et en entraîne d’autres dans son flux de recommandation, selon la logique autophagique des systèmes de recommandation. Pour l’analyste Ben Thompson, l’IA générative est un parfait moteur pour produire de la publicité – et ces slops sont-ils autre chose que des contenus à la recherche de revenus ? Comme le dit le philosophe Rob Horning : « le rêve de longue date d’une quantité infinie de publicités inondant le monde n’a jamais semblé aussi proche ». Pour Jason Koebler de 404 Media, qui a enquêté toute l’année sur l’origine de ce spam IA, celui-ci est profondément relié au modèle économique des réseaux sociaux qui rémunèrent selon l’audience que les créateurs réalisent, ce qui motive d’innombrables utilisateurs à chercher à en tirer profit. Koebler parle d’ailleurs d’internet zombie pour qualifier autant cette génération de contenu automatisée que les engagements tout aussi automatisés qu’elle génère. Désormais, ce ne sont d’ailleurs plus les contenus qui sont colonisés par ce spam, que les influenceurs eux-mêmes, notamment par le biais de mannequins en maillots de bains générés par l’IA. À terme, s’inquiète Koebler, les médias sociaux pourraient ne plus rien avoir de sociaux et devenir des espaces « où le contenu généré par l’IA éclipse celui des humains », d’autant que la visibilité de ces comptes se fait au détriment de ceux pilotés par des humains. Des sortes de régies publicitaires sous stéroïdes. Comme l’explique une créatrice de contenus adultes dont l’audience a chuté depuis l’explosion des mannequins artificiels : « je suis en concurrence avec quelque chose qui n’est pas naturel ». Ces contenus qui sont en train de coloniser les réseaux sociaux n’ont pas l’air d’inquiéter les barons de la tech, pointait très récemment Koebler en rapportant les propose de Mark Zuckerberg. D’autant que ces contenus génératifs semblent produire ce qu’on attend d’eux. Meta a annoncé une augmentation de 8 % du temps passé sur Facebook et de 6 % du temps passé sur Instagram grâce aux contenus génératifs. 15 millions de publicités par mois sur les plateformes Meta utilisent déjà l’IA générative. Et Meta prévoit des outils pour démultiplier les utilisateurs synthétiques. Le slop a également envahi la plateforme de blogs Medium, explique Wired, mais ces contenus pour l’instant demeurent assez invisibles, notamment parce que la plateforme parvient à limiter leur portée. Un endiguement qui pourrait ne pas résister au temps. À terme, les contenus produits par les humains pourraient devenir de plus en plus difficiles à trouver sur des plateformes submergées par l’IA. On voudrait croire que les réseaux sociaux puissent finir par s’effondrer du désintérêt que ces contenus démultiplient. Il semble que ce soit l’inverse, l’internet zombie est en plein boom. Tant et si bien qu’on peut se demander, un an après le constat de l’effondrement de l’information, si nous ne sommes pas en train de voir apparaître l’effondrement de tout le reste ? Les enjeux du remplissage par le vide Dans sa newsletter personnelle, le chercheur et artiste Eryk Salvaggio revient à son tour sur le remplissage par l’IA, dans trois longs billets en tout point passionnants. Il souligne d’abord que ce remplissage sait parfaitement s’adapter aux algorithmes des médias sociaux. Sur Linked-in, les contenus rédigés par des LLM seraient déjà majoritaires. Même le moteur de recherche de Google valorise déjà les images et les textes générés par IA. Pour Salvaggio, avec l’IA générative toute information devient du bruit. Mais surtout, en se jouant parfaitement des filtres algorithmiques, celle-ci se révèle parfaitement efficace pour nous submerger. Jesus Schrimp, image symbolique des eaux troubles de l’IA produisant son propre vide. Salvaggio propose d’abandonner l’idée de définir l’IA comme une technologie. Elle est devenue un projet idéologique, c’est-à-dire que « c’est une façon d’imaginer le monde qui devient un raccourci pour expliquer le monde ». Et elle est d’autant plus idéologique selon les endroits où elle se déploie, notamment quand c’est pour gérer des questions sociales ou culturelles. « L’optimisation de la capacité d’un système à affirmer son autorité est une promesse utopique brillante des technologies d’automatisation ». « L’un des aspects de l’IA en tant qu’idéologie est donc la stérilisation scientifique de la variété et de l’imprévisibilité au nom de comportements fiables et prévisibles. L’IA, pour cette raison, offre peu et nuit beaucoup au dynamisme des systèmes socioculturels ». Les gens participent à l’idéologie de l’IA en évangélisant ses produits, en diffusant ses résultats et en soutenant ses avancées pour s’identifier au groupe dominant qui l’a produit. La production par l’IA de contenus de remplissage nécessite de se demander à qui profite ce remplissage abscons ? Pour Salvaggio, le remplissage est un symptôme qui émerge de l’infrastructure même de l’IA qui est elle-même le résultat de l’idéologie de l’IA. Pourquoi les médias algorithmiques récompensent-ils la circulation de ces contenus ? Des productions sensibles, virales, qui jouent de l’émotion sans égard pour la vérité. Les productions de remplissage permettent de produire un monde tel qu’il est imaginé. Elles permettent de contourner tout désir de comprendre le monde, car elle nous offre la satisfaction immédiate d’avoir un « sentiment sur le monde ». « L’AI Slop est un signal vide et consommé passivement, un symptôme de « l’ère du bruit », dans lequel il y a tellement de « vérité » provenant de tant de positions que l’évaluation de la réalité semble sans espoir. » Notre désorientation par le vide Eryk Salvaggio se demande même si le but de l’IA n’est pas justement de produire ce remplissage. Un remplissage « équipé », « armé », qui permet d’essaimer quelque chose qui le dépasse, comme quand l’IA est utilisée pour inonder les réseaux de contenus sexuels pour mieux essaimer le regard masculin. Les productions de l’IA permettent de produire une perspective, un « regard en essaim » qui permet de manipuler les symboles, de les détourner. « Les images générées par l’IA offrent le pouvoir de façonner le sens dans un monde où les gens craignent l’impuissance et l’absence de sens en les invitant à rendre les autres aussi impuissants et dénués de sens qu’eux ». Ces images « diminuent la valeur de la réalité », suggère brillamment Salvaggio. Elles créent « une esthétisation », c’est-à-dire rend la représentation conforme à un idéal. La fonction politique de ce remplissage va bien au-delà des seules représentations et des symboles, suggère-t-il encore. L’IA appliquée aux services gouvernementaux, comme les services sociaux, les transforme à leur tour « en exercice esthétique ». Notre éligibilité à une assurance maladie ou à une couverture sociale n’est pas différente de l’IA Slop. C’est cette même infrastructure vide de sens qui est pointée du doigt par ceux qui s’opposent à l’algorithmisation de l’Etat que ceux qui fuient les boucles de rétroactions délétères des médias sociaux. Le projet DOGE d’Elon Musk, ce département de l’efficacité gouvernementale qui devrait proposer un tableau de bord permettant aux internautes de voter pour éliminer les dépenses publiques les plus inutiles, semble lui-même une forme de fusion de médias sociaux, d’idéologie de l’IA et de pouvoir pour exploiter le regard en essaim de la population et le diriger pour harceler les fonctionnaires, réduire l’État providence autour d’une acception de l’efficacité ultra-réductrice. Au final, cela produit une forme de politique qui traite le gouvernement comme une interface de médias sociaux, conçue pour amplifier l’indignation, intimider ceux qui ne sont pas d’accord et rendre tout dialogue constructif impossible. Bienvenue à la « momusocratie » , le gouvernement des trolls, de la raillerie, explique Salvaggio, cette Tyrannie des bouffons chère à l’essayiste Christian Salmon. Mais encore, défend Salvaggio, le déversement de contenus produit par l’IA générative promet un épuisement du public par une pollution informationnelle sans précédent, permettant de perturber les canaux d’organisation, de réflexion et de connexion. « Contrôlez le filtre permet de l’orienter dans le sens que vous voulez ». Mais plus que lui donner un sens, la pollution de l’information permet de la saturer pour mieux désorienter tout le monde. Cette saturation est un excellent moyen de garantir « qu’aucun consensus, aucun compromis, ou simplement aucune compréhension mutuelle ne se produise ». Cette saturation ne vise rien d’autre que de promouvoir « la division par l’épuisement ». « Le remplissage est un pouvoir ». « L’idéologie de l’IA fonctionne comme une croyance apolitique trompeuse selon laquelle les algorithmes sont une solution à la politique » qui suppose que les calculs peuvent prendre les décisions au profit de tous alors que leurs décisions ne sont qu’au profit de certains, en filtrant les données, les idées, les gens qui contredisent les résultats attendus. Alors que l’élection de Trump éloigne les enjeux de transparence et de régulation, l’IA va surtout permettre de renforcer l’opacité qui lui assure sa domination. Vers un monde sans intérêt en boucle sur lui-même Dans la dernière partie de sa réflexion, Salvaggio estime que le remplissage est un symptôme, mais qui va produire des effets très concrets, des « expériences désintéressées », c’est-à-dire des « expériences sans intérêt et incapables de s’intéresser à quoi que ce soit ». C’est le rêve de machines rationnelles et impartiales, omniscientes, désintéressées et qui justement ne sont capables de s’intéresser à rien. Un monde où l’on confie les enfants à des tuteurs virtuels par souci d’efficacité, sans être capable de comprendre tout ce que cette absence d’humanité charrie de délétère. L’IA s’est construite sur l’excès d’information… dans le but d’en produire encore davantage. Les médias sociaux ayant été une grande source de données pour l’IA, on comprend que les contenus de remplissage de l’IA soient optimisés pour ceux-ci. « Entraînée sur du contenu viral, l’IA produit du contenu qui coche toutes les cases pour l’amplification. Le slop de l’IA est donc le reflet de ce que voient nos filtres de médias sociaux. Et lorsque les algorithmes des médias sociaux en reçoivent les résultats, il les reconnaît comme plus susceptibles de stimuler l’engagement et les renforce vers les flux (générant plus d’engagement encore). » Dans le tonneau des Danaïdes de l’amplification, l’IA slop est le fluidifiant ultime, le contenu absurde qui fait tourner la machine sans fin. Combattre ce remplissage par l’IA n’est une priorité ni pour les entreprises d’IA qui y trouvent des débouchés, ni pour les entreprises de médias sociaux, puisqu’il ne leur porte aucun préjudice. « Les contenus de remplissage de l’IA sont en fait la manifestation esthétique de la culture à médiation algorithmique » : « ils sont stylisés à travers plus d’une décennie d’algorithmes d’optimisation qui apprennent ce qui pousse les gens à s’engager ». Face à ces contenus « optimisés pour performer », les artistes comme les individus qui ont tenté de partager leur travail sur les plateformes sociales ces dernières années ne peuvent pas entrer en concurrence. Ceux qui ont essayé s’y sont vite épuisés, puisqu’il faut tenir d’abord le rythme de publication infernal et infatigable que ces systèmes sont capables de produire. Dépouiller les symboles de leur relation à la réalité « Les images générées par l’IA peuvent être interprétées comme de l’art populaire pour servir le populisme de l’IA ». Elles visent à « dépouiller les symboles de leur relation à la réalité » pour les réorganiser librement. Les gens ne connaissent pas les films mais ont vu les mèmes. Le résultat de ces images est souvent critiqué comme étant sans âme. Et en effet, le texte et les images générés par l’IA souffrent de l’absence du poids du réel, dû à l’absence de logique qui préside à leur production. « L’ère de l’information est arrivée à son terme, et avec elle vient la fin de toute définition « objective » et « neutre » possible de la « vérité ». » L’esthétique du remplissage par l’IA n’est pas aléatoire, mais stochastique, c’est-à-dire qu’elle repose sur une variété infinie limitée par un ensemble de règles étroites et cohérentes. Cela limite notre capacité à découvrir ou à inventer de nouvelles formes de culture, puisque celle-ci est d’abord invitée à se reproduire sans cesse, à se moyenniser, à s’imiter elle-même. Les images comme les textes de l’IA reflètent le pouvoir de systèmes que nous avons encore du mal à percevoir. Ils produisent des formes de vérités universalisées, moyennisées qui nous y enferment. Comme dans une forme d’exploitation sans fin de nos représentations, alors qu’on voudrait pouvoir en sortir, comme l’expliquait dans une note pour la fondation Jean Jaurès, Melkom Boghossian, en cherchant à comprendre en quoi les algorithmes accentuent les clivages de genre. Comme s’il devenait impossible de se libérer des contraintes de genres à mesure que nos outils les exploitent et les renforcent. Cet internet de contenus absurde n’est pas vide, il est plein de sens qui nous échappent et nous y engluent. Il est plein d’un monde saturé de lui-même. A mesure que l’IA étend son emprise sur la toile, on se demande s’il restera encore des endroits où nous en serons préservés, où nous pourrons être mis en relation avec d’autres humains, sans que tout ce qui encode les systèmes ne nous déforment. Du remplissage à la fin de la connaissance Dans une tribune pour PubliBooks, la sociologue Janet Vertesi estime que les recherches en ligne sont devenues tellement chaotiques et irrationnelles, qu’elle a désormais recours aux dictionnaires et encyclopédies papier. « Google qui a fait fortune en nous aidant à nous frayer un chemin sur Internet se noie désormais dans ses propres absurdités générées par elle-même ». Nous voici confrontés à un problème d’épistémologie, c’est-à-dire de connaissance, pour savoir ce qui est réel et ce qui ne l’est pas. Au XXᵉ siècle, les philosophes ont défini la connaissance comme une croyance vraie justifiée. La méthode scientifique était le moyen pour distinguer la bonne science de la mauvaise, la vérité du mensonge. Mais cette approche suppose souvent qu’il n’y aurait qu’une seule bonne réponse que nous pourrions connaître si nous adoptons les bonnes méthodes et les bons outils. C’est oublier pourtant que la connaissance ne sont pas toujours indépendantes de l’expérience. Ludwig Wittgenstein a utilisé la figure du canard-lapin pour montrer comment des personnes rationnelles pouvaient en venir à avoir des points de vue irréconciliablement différents sur une même réalité. Les épistémologues se sont appuyés sur cette idée pour montrer que les personnes, selon leurs positions sociales, ont des expériences différentes de la réalité et que la connaissance objective ne pouvait naître que de la cartographie de ces multiples positions. Les sociologues de la connaissance, eux, examinent comment différents groupes sociaux en viennent à légitimer différentes manières de comprendre, souvent à l’exclusion des autres. Cela permet de comprendre comment différents faits sociaux circulent, s’affrontent ou se font concurrence, et pourquoi, dans les luttes pour la vérité, ceux qui détiennent le pouvoir l’emportent si souvent… Imposant leurs vérités sur les autres. Mais ces questions ne faisaient pas partie des préoccupations de ceux qui ont construit internet, ni des systèmes d’IA générative qui s’en nourrissent. Depuis l’origine, internet traite toutes les informations de manière égale. Le réseau ne consiste qu’à acheminer des paquets d’informations parfaitement égaux entre eux, rappelle la sociologue. À cette neutralité de l’information s’est ajoutée une autre métaphore : celle du marché des idées, où chaque idée se dispute à égalité notre attention. Comme dans le mythe du libre marché, on a pu penser naïvement que les meilleures idées l’emporteraient. Mais ce régime épistémique a surtout été le reflet des croyances de l’Amérique contemporaine : un système de connaissance gouverné par une main invisible du marché et entretenue par des conservateurs pour leur permettre de générer une marge bénéficiaire. « Pourtant, la connaissance n’est pas une marchandise. La « croyance vraie justifiée » ne résulte pas non plus d’une fonction d’optimisation. La connaissance peut être affinée par le questionnement ou la falsification, mais elle ne s’améliore pas en entrant en compétition avec la non-connaissance intentionnelle. Au contraire, face à la non-connaissance, la connaissance perd. » L’interrogation du monde par des mécanismes organisés, méthodiques et significatifs – comme la méthode scientifique – peut également tomber dans le piège des modes de connaissance fantômes et des impostures méthodologiques. « Lorsque toute information est plate – technologiquement et épistémologiquement – il n’y a aucun moyen d’interroger sa profondeur, ses contours ou leur absence ». En fait, « au lieu d’être organisé autour de l’information, l’Internet contemporain est organisé autour du contenu : des paquets échangeables, non pondérés par la véracité de leur substance. Contrairement à la connaissance, tout contenu est plat. Aucun n’est plus ou moins justifié pour déterminer la vraie croyance. Rien de tout cela, au fond, n’est de l’information. » « En conséquence, nos vies sont consumées par la consommation de contenu, mais nous ne reconnaissons plus la vérité lorsque nous la voyons. Et lorsque nous ne savons pas comment peser différentes vérités, ou coordonner différentes expériences du monde réel pour regarder derrière le voile, il y a soit une cacophonie, soit un seul vainqueur : la voix la plus forte qui l’emporte. » Contrairement à Wikipédia, encore relativement organisé, le reste du Web est devenu la proie de l’optimisation des moteurs de recherche, des technologies de classement et de l’amplification algorithmique, qui n’ont fait que promouvoir le plus promouvable, le plus rentable, le plus scandaleux. « Mais aucun de ces superlatifs n’est synonyme de connaissance ». Les systèmes qui nous fournissent nos informations ne peuvent ni mesurer ni optimiser ce qui est vrai. Ils ne s’intéressent qu’à ce sur quoi nous cliquons. Et le clou dans le cercueil est enfoncé par l’intelligence artificielle qui « inonde Internet de contenu automatisé plus rapidement que l’on ne peut licencier une rédaction ». Dans ce paysage sous stéroïdes, aucun système n’est capable de distinguer la désinformation de l’information. Les deux sont réduits à des paquets de même poids cherchant leur optimisation sur le marché libre des idées. Et les deux sont ingérés par une grande machinerie statistique qui ne pèse que notre incapacité à les distinguer. Aucun système fondé sur ces hypothèses ne peut espérer distinguer la « désinformation » de « l’information » : les deux sont réduites à des paquets de contenu de même valeur, cherchant simplement une fonction d’optimisation dans un marché libre des idées. Et les deux sont également ingérées dans une grande machinerie statistique, qui ne pèse que notre incapacité à les discerner. Le résultat ne promet rien d’autre qu’un torrent indistinct et sans fin, « où la connaissance n’a jamais été un facteur et d’où la connaissance ne peut donc jamais émerger légitimement ». « Sans topologie de l’information, nous sommes à la dérive dans le contenu, essayant en vain de naviguer dans une cascade d’absurdités sans boussole ». « Il est grand temps de revenir à ces méthodes et à ces questions, aux milliers d’années de gestion de l’information et d’échange de connaissances qui ont transmis non seulement des faits ou du contenu, mais aussi une appréciation de ce qu’il faut pour faire émerger des vérités », plaide Vertesi. « Il n’est pas nécessaire que ce soit un projet colonial ou réductionniste. Les connaissances d’aujourd’hui sont plurielles, distribuées, issues de nombreux lieux et peuples, chacun avec des méthodes et des forces d’ancrage uniques. Cela ne signifie pas non plus que tout est permis. Le défi consiste à s’écouter les uns les autres et à intégrer des perspectives conflictuelles avec grâce et attention, et non à crier plus fort que les autres ». « Alors que nos vies sont de plus en plus infectées par des systèmes d’IA maladroits et pilleurs et leurs flux hallucinatoires, nous devons apprendre à évaluer plutôt qu’à accepter, à synthétiser plutôt qu’à résumer, à apprécier plutôt qu’à accepter, à considérer plutôt qu’à consommer ». « Notre paysage technologique contemporain exige de toute urgence que nous revenions à une autre des plus anciennes questions de toutes : « Qu’est-ce qui est vraiment réel ? » » Afficher l’article complet
- La dernière semaine
-
franz a réagi à un message dans un sujet :
Maxthon 7.3.1.5000 Bêta pour Windows est sorti
-
franz a réagi à un message dans un sujet :
Maxthon 7.3.1.5000 Bêta pour Windows est sorti
-
 ErnestR4 a réagi à un message dans un sujet :
Traduction française de Mx7 pour Windows
ErnestR4 a réagi à un message dans un sujet :
Traduction française de Mx7 pour Windows
-
Ldfa a réagi à un message dans un sujet :
Traduction française de Mx7 pour Windows
-

Win Traduction française de Mx7 pour Windows
POLAURENT a répondu à un(e) sujet de Ldfa dans Traductions françaises de Maxthon sur Crowdin
itou ! -
Je termine encore Platine cette semaine.
-
Je termine encore Platine cette semaine.
-
durée de lecture : 3 min Je suis content d’avoir investi dans un Mac Studio pour faire tourner des modèles IA un peu plus balèzes du coup, je surveille un peu ce qui sort en ce moment comme modèles, notamment pour coder, et voilà que la famille de modèles Qwen3 vient d’être officiellement lancée, et franchement, ça a l’air plutôt pas mal ! Surtout si vous aimez jouer avec du LLM sans passer par les API payantes de géants de la tech comme OpenAI. Qwen3 (prononcez “Tchwen”, ça fait plus cool en soirée) est donc la nouvelle génération de modèles développée par Alibaba, qui débarque avec des performances assez bluffantes, surtout quand on regarde le rapport puissance / ressources nécessaires. Cette famille comprend 8 modèles différents, dont 2 utilisant l’architecture MoE (Mixture-of-Experts) et 6 modèles dits “denses” (plus classiques), avec des tailles allant de 0,6B à 235B de paramètres. Autrement dit, il y en a pour tous les goûts et toutes les configurations, que vous ayez un PC de gamer dernier cri ou juste un portable un peu costaud. Celui qui se démarque dans cette famille, c’est Qwen3-30B-A3B, qui est un modèle à 30 milliards de paramètres et qui a été optimisé pour fonctionner à la vitesse d’un modèle de… 3 milliards de paramètres ! Un petit miracle d’ingénierie qui permet enfin d’avoir le beurre (la qualité d’un gros modèle) et l’argent du beurre (la vitesse d’un petit modèle). Et Qwen3 se défend plutôt bien face à la concurrence puisque son modèle phare, Qwen3-235B-A22B (qui est en fait un modèle de 235 milliards de paramètres optimisé pour tourner comme un modèle de 22 milliards), se place dans la même ligue que DeepSeek-R1 et les modèles d’OpenAI comme o1 et o3-mini. Il les dépasse même sur certains benchmarks ! Dans le détail, Qwen3-235B-A22B a obtenu des scores impressionnants sur ArenaHard (95,6%), AIME'24 (85,7%), LiveBench (77,1%) et MultiIF (71,9%). Pour les non-initiés qui me lisent, ces tests mesurent respectivement la capacité de raisonnement général, les compétences en mathématiques, la performance globale et les capacités multilingues. Dans tous ces domaines le modèle chinois surpasse ses concurrents directs et supporte même 119 langues et autres dialectes. Top pour faire des traductions ou discuter avec lui dans votre langue natale, hein les biloutes du 59 ! Une autre fonctionnalité intéressante est ce qu’ils appellent le “mode de pensée mixte” qui vous permet de demander au modèle de basculer entre un “mode réflexion” (où il détaille son raisonnement étape par étape, idéal pour les problèmes complexes) et un “mode rapide” (où il donne directement la réponse, parfait pour les questions simples). Ce contrôle se fait via des balises comme “/think” et “/no_think” et pour les plus codeurs d’entre vous, sachez que Qwen3 se débrouille également très bien en programmation. Sur l’échelle Elo de Codeforces, le modèle principal atteint même un score de 2056, soit le même niveau que DeepSeek-R1 (2029) et OpenAI-o3-mini (2036). Et le plus cool, c’est que tous ces modèles sont distribués sous licence Apache 2.0 donc vous pouvez l’utiliser à des fins commerciales sans avoir à verser des royalties ou à demander une autorisation spéciale (contrairement à Llama de Meta) !! Par contre, n’oubliez pas que c’est du 100% chinois, donc comme pour les modèles américains, prudence est mère de sureté. Maintenant pour ceux qui se demandent comment ces modèles ont été entraînés, et bien ils ont été gavé de 36 trillions de tokens (unités de texte) soit l’équivalent de plusieurs dizaines de milliers de livres, articles scientifiques, lignes de code et autres contenus spécialisés (v’la la gueule des ayants-droits…). Un vrai Bouffe-tout ce Qwen 3 ! Le modèle supporte également les extensions multimodales, ce qui signifie qu’il peut traiter non seulement du texte, mais aussi du code, de l’audio et des images. Il est également équipé pour les fonctionnalités d’agent, donc peut tout à fait utiliser des outils externes pour accomplir des tâches plus complexes. Bref tout cela en fait un modèle très intéressant donc si vous avez une carte graphique récente avec suffisamment de VRAM (idéalement une RTX de série 30 ou 40 avec au moins 16 Go), vous allez pouvoir vous amuser avec ! C’est même déjà dispo via Ollama et contrairement aux services cloud, vos données resteront chez vous, ce qui est quand même un gros avantage !! Amusez-vous bien ! Source Afficher l’article complet
-
Win Traduction française de Mx7 pour Windows
Ldfa a répondu à un(e) sujet de Ldfa dans Traductions françaises de Maxthon sur Crowdin
C'est validé. fr.ini -
Win Traduction française de Mx7 pour Windows
ErnestR4 a répondu à un(e) sujet de Ldfa dans Traductions françaises de Maxthon sur Crowdin
Voté -
Win Traduction française de Mx7 pour Windows
Ldfa a répondu à un(e) sujet de Ldfa dans Traductions françaises de Maxthon sur Crowdin
There are new strings to translate in the Maxthon pour Windows project. You were a project participant previously so your help will be appreciated a lot. 3 new strings for translation (9 words). - Avant
-
Changements principaux : * Optimisation de la logique d'installation de l'application PWA uuGPT avec prise en charge de la désinstallation via mx://apps. * Ajustement de la largeur minimale de la fenêtre pour les applications PWA afin d'améliorer la qualité de l'affichage. * Résolution des problèmes liés à la largeur des menus en fixant la largeur maximale des menus. - Correction de la vulnérabilité critique CVE-2025-2783 pour améliorer la sécurité. - Résolution du problème d'initialisation sans données dans les notes pour améliorer la stabilité. - Correction du problème d'icône vide avec les raccourcis Maxthon pour une meilleure expérience utilisateur.
-
Maxthon 7.3.1.5000 Bêta pour Windows est sorti aujourd'hui, il apporte son lot de nouvelles fonctionnalités / améliorations et de corrections de bugs. Téléchargement : https://github.com/maxthon/Maxthon/releases Les changements en français sont là. Vous pouvez également vous abonner au groupe Telegram NBdomain & MX6 pour faire remonter vos demandes d'améliorations et bugs rencontrés. Source : https://forum.maxthon.com/index.php?/topic/29267-maxthon-pc-7315000-beta/
-
Navigateur Web Perplexity l’assume : son navigateur Comet sera un aspirateur à données personnelles
ErnestR4 a répondu à un(e) sujet de Ldfa dans Et la famille Webkit alors...
J'ai aussi demandé : Est-ce que comet aura accès à mon compte ouvert ici? Réponse : Comet, le navigateur développé par Perplexity, devrait permettre aux utilisateurs de se connecter avec leur compte Perplexity existant, tout comme vous le faites actuellement sur l’application web ou mobile. Cela signifie que si vous avez déjà un compte ouvert ici, vous pourrez l’utiliser sur Comet pour retrouver vos paramètres, vos fils de discussion et vos préférences, assurant ainsi une continuité de votre expérience utilisateur16. En général, les produits Perplexity sont conçus pour fonctionner de manière intégrée afin que vos données, abonnements (comme Perplexity Pro), et historiques restent accessibles sur toutes les plateformes où vous vous connectez avec le même compte1. Toutefois, chaque plateforme respecte vos contrôles de confidentialité et vous permet de gérer la synchronisation ou la confidentialité de vos données selon vos préférences. Par exemple, Comet propose différents niveaux de gestion de la vie privée, dont un mode local où aucune donnée n’est envoyée dans le cloud sans votre consentement explicite2. En résumé, oui, Comet aura accès à votre compte Perplexity existant si vous vous connectez avec les mêmes identifiants, et vous conserverez le contrôle sur l’utilisation et la confidentialité de vos données. Donc faudra mieux, si on essaye Comet, ouvrir un autre compte dans Comet -
Navigateur Web Perplexity l’assume : son navigateur Comet sera un aspirateur à données personnelles
ErnestR4 a répondu à un(e) sujet de Ldfa dans Et la famille Webkit alors...
Du coup question à Perplexity AI : Est-ce que vous resterez accessible en dehors de comet Réponse : "Oui, Perplexity restera accessible en dehors de Comet. Comet est un nouveau navigateur web développé par Perplexity, mais il ne remplace pas l’accès classique au moteur de recherche conversationnel Perplexity que vous utilisez actuellement. Le lancement de Comet, prévu pour mai 2025, s’inscrit dans une stratégie d’expansion, mais Perplexity continuera d’exister sous forme d’application web indépendante, accessible via les navigateurs traditionnels comme Chrome, Firefox ou Safari. Le navigateur Comet proposera des fonctionnalités supplémentaires, notamment une intégration plus poussée de l’IA et un suivi contextuel plus riche, mais il s’agit d’une offre complémentaire. Les utilisateurs pourront donc continuer à utiliser Perplexity sans passer par Comet, selon leurs préférences et leurs besoins."" Donc à surveiller 🧐 -
Navigateur Web Perplexity l’assume : son navigateur Comet sera un aspirateur à données personnelles
Ldfa a répondu à un(e) sujet de Ldfa dans Et la famille Webkit alors...
https://www.01net.com/actualites/perplexity-donnees-pub-ciblee-ambition-decomplexee-startup-ia.html -
Perplexity l’assume : son navigateur Comet sera un aspirateur à données personnelles Pour des publicités plus ciblées que jamais Surtout connue pour son moteur de recherche conversationnel, la startup Perplexity prépare le lancement de son propre navigateur web, Comet. Mais, loin des discours habituels plutôt portés sur la protection de la vie privée, son PDG Aravind Srinivas a décidé d’afficher clairement la couleur : collecter un maximum de données utilisateurs pour affiner le ciblage publicitaire... Source : https://www.lesnumeriques.com/intelligence-artificielle/perplexity-l-assume-son-navigateur-comet-sera-un-aspirateur-a-donnees-personnelles-n235986.html
-
Chromium Navigateur Internet CatsXP, la relève de Maxthon ?
Ldfa a posté un sujet dans Et la famille Webkit alors...
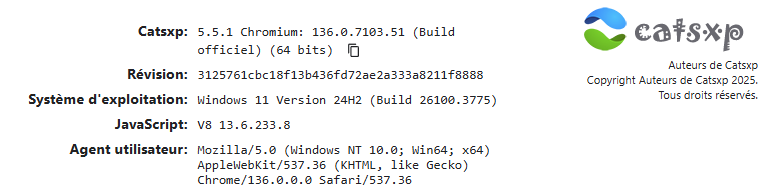
En consultant le FI, je suis tombé sur le nom d'un nouveau navigateur Internet que je ne connaissais pas, il se nomme CatsXP. Je l'ai installé en version Portable pour le tester et il a l'air vraiment pas mal du tout. La version du noyau de Chromium est à jour, son développement a débuté en fin 2020, il est très personnalisable, d'origine chinoise comme Maxthon. Il met en avant la protection de la vie privée, la sécurité et la rapidité, il propose les onglets à la verticale ou à l'horizontale, la possibilité de créer des profils, les gestes de la souris et le super glisser-déposer à la Maxthon, le support des extensions de Chrome, un bloqueur de pubs intégré comme Mx5, il propose des versions pour Windows et MacOs, la possibilité de synchroniser les données entre plusieurs ordinateurs et il est entièrement traduit en français. À essayer donc... Source : https://www.catsxp.com/
-
J'en ai rajouté 2 autres depuis...
-
Wao y a du monde hihi.
-
Je termine encore Platine cette semaine.
-
Je termine encore Platine cette semaine.
-
👏